
上周,Google 在曼谷举办了为期三天的 Search Central Live Deep Dive APAC 2025,大会主题分别是抓取(Crawling)、索引(Indexing)、展现(Serving),讲了很多底层逻辑,也给出了不少实操细节。
我们整理这篇超长干货,是因为SEO这行,最能让人沉下心思考的,有时候还是文字内容。
信息越碎,越需要系统梳理;节奏越快,越不能停下学习。
当然我们也要提醒各位一句,Google 的说法,并非 100% 正确。SEO 很多时候没有绝对的对错,建立自己的判断与SEO价值观非常重要。
这篇内容信息量超密,耗费了我们大量时间与精力。如果你觉得内容对你有用,别忘了点赞支持,转发给更多需要的人!
如果你已经准备好了,那我们就直接开始:
Day 1:Crawling(抓取)
关键词:AI 展现基础设施、Gen Z(Z 世代)入口迁移、多模态结构化内容、抓取预算逻辑(crawl budget)、Search Console 定位…
一句话总结:
AI 正在改变用户的搜索起点,但 Google 搜索的抓取、排序与理解逻辑并未重写——高质量、为人而写的内容,依然是系统唯一可信的起点。
一个常被忽视的事实:
AI 展现频繁触发,并不意味着你要为 AI 写内容。Google 搜索不会用 AI 生成文本训练排序系统,真正的目标读者仍然是人,不是模型。
搜索已进入拐点
Mike Jittivanich 提出搜索正处于“三大驱动力”交汇点:
1. AI 创新,影响程度接近移动/社交大迁移 2. 用户期待更快、更自然、更对话式的搜索体验 3. Z 世代(Gen Z)的搜索行为与父辈完全不同
用户不再满足于传统蓝色链接(blue links),搜索团队面临的挑战是:如何让 AI 展现、图像召回等新形态与蓝链并行编织,在一个界面中同时呈现又不冲突。

AI Overviews 不是另一套搜索系统
- Googlebot 同时负责传统蓝色链接与 AI 特性内容的抓取(crawling)
- AI Overviews 与 AI Mode(AI 模式)与蓝链共用同一基础架构(抓取、索引、展现)
- 同一体系中的其他爬虫服务于 Gemini 和大语言模型(LLMs)
- 所有页面均经历统一流程:HTML 解析、渲染(rendering)、去重(deduplication)、排序信号(ranking signals)处理与垃圾检测(SpamBrain)
Google 正在将 DeepMind 的推理模型(reasoning models)引入搜索系统,以支持跨模态、多步骤、任务型的回答体验,例如 AI Mode 中的购物、餐饮规划和路径生成

人类写作仍是排名基础
• 排名系统不会在 AI 生成内容上进行训练 • AI 生成文本可被索引(indexing),但不被用作模型训练样本 • 排名模型仍以人类创作的高质量网页为基础,具备自然语言、结构清晰、信息可靠等特征
多模态内容是基础配置,不再是加分项
• 图片应添加语义明确的 alt 属性 • 视频建议附字幕或文字转写 • 页面语言建议具有对话式特征,适配语音查询和自然语言处理 • 搜索触点正在碎片化,内容需覆盖视觉、听觉、语义多个模态入口
Z 世代正在绕开搜索框
• Google Lens 搜索同比增长 65%,2025 年累计超过 1000 亿次,其中约 20% 携带商业意图 • 约 10% 的 Gen Z 搜索旅程始于 Circle to Search(圈选搜索)或其他 AI 功能入口 • 搜索入口不再限于文本框,内容需适配图像起始、语音起始等非线性路径

Search Console 的数据节奏与定位
• 数据延迟约 2 天(基于太平洋时区) • 近实时数据与最终数据可能存在 ±1% 偏差 • “建议”功能面向非专业用户,提供模块化、操作性强的优化建议 • 功能生命周期:用户需求 → 数据准备 → 设计开发 → 测试上线 • Search Console 是 Google 搜索基础设施与网站之间的桥梁(bridge),可用于:
• 诊断抓取问题 • 跟踪搜索表现 • 识别是否符合 AI 展现触发条件
抓取预算的计算机制(crawl budget)
• 抓取预算 = 抓取速率上限(crawl rate limit) × 抓取需求(crawl demand) • 只有 HTTP 5xx(服务器错误)会真正消耗抓取预算 • HTTP 4xx(客户端错误)不消耗预算,但会影响调度优先级 • 存在断链、响应缓慢会拖慢整体抓取效率 • AI 特性可能增加抓取频率,但抓取频率增加不代表排名提升
长查询结构崛起
• 五词以上的自然语言查询增长速度为短查询的 1.5 倍 • 用户倾向以问题、任务形式表达搜索意图 • 内容组织结构应支持问题化、场景化、任务导向的表达方式
LLMs.txt:Google 明确不参与
• LLMs.txt 是由 IETF 提出的行业标准草案,Google 不参与也不计划采纳 • 官方仍建议使用 robots.txt 控制抓取行为 • 但需注意:并非所有 AI 爬虫都会遵守 robots.txt 协议
AI 并非搜索系统的例外用户
• 所有页面内容,无论是否用于 AI 展现,均走统一流程:HTML 解析、渲染、去重、BERT 分析、MUM 推理、垃圾识别等 • 查询解析与内容评分机制一致 • 差别仅体现在最终展现形式,是蓝色链接,还是 AI Overviews/AI Mode 的生成模块
Day 2:Indexing(索引)
关键词:Indexing、主内容识别、重复内容聚类、爬虫控制、信号提取、Structured Data、SpamBrain、软 404、Google Trends API
一句话总结: 索引的本质判断标准,始终是“有没有被看作对用户有用”,而不是“有没有被技术手段发现”。
一个常被忽视的提醒: 不是每 个设置了rel=cano nical的页面,Google 都会听你的。决定权仍在它手上,顺序是防劫持 > 用户体验 > 站长信号。
Google 如何理解网页内容
- HTML 会被标准化成 DOM,再识别导航、标题、主内容区块。
- 主内容可以是文字、图片、视频,甚至是功能型模块(比如计算器)。
- JavaScript 渲染后才会进入下一步的索引判断。
- 系统会提取
rel=canonical、hreflang、meta robots等结构信息。 - 与样式、导航无关的页面核心内容,会被单独抽取用于后续处理。
- 搜索团队依然强调内容结构的直观性,系统不会优先处理响应式或自适应布局,两者一视同仁。
- Google 在解析内容时,会将 HTML 分词为 Token,用于构建索引。该分词系统源于 2001 年东京办公室,也复用到了 AI 产品中。
主内容的区位影响排名
一个典型案例是:“将 Hugo 7 这个词从侧边栏挪到正文后,页面整体可见度提升明显。” 系统更信任主内容区域中的词汇,尤其是标题、副标题、正文前几段。如果页面结构混乱,爬虫可能会误判重要信息的位置。
去重策略与 canonical 的优先级排序
Google 判断重复内容,主要靠三组技术:301/302 重定向、内容相似度、rel=canonical 。 但 Google 会先判断是否存在被劫持风险,再参考用户体验,最后才参考站长的 canonical 指令。 即使你设置了 canonical,也可能不是最终被选中的版本。 某些“软错误页面”或模板生成页可能会拉低整个聚类的信任度。

Soft 404 是怎么定义的?
如果一个页面看起来存在,但核心内容极其稀薄或无用,Google 会认为它是 “soft 404”。 系统会标记一个 centerpiece annotation ,说明问题是出在主内容,而不是技术错误。 一旦页面被标注为 soft 404,整个聚类都有可能受影响。 Google 判断页面质量时,不仅考虑页面本身的“有用性”,也看其“可信度”是否成立。
控制索引的几种方式(并不都生效)
• robots.txt :控制爬虫“能不能抓”页面内容。 • meta robots :控制已抓页面是否允许进入索引,比如 noindex 、 noimageindex 。 • none 指令 = noindex, nofollow ,写法简化,但效果一致。 • unavailable_after 依然有效,虽然原团队已离职。可用于让限时活动、过期促销等页面在特定时间后自动退出索引,避免在 AI 特性中长期残留,误导用户或影响品牌认知。 • notranslate :Chrome 将不再提示翻译此页。
Structured Data 可以用,但别乱用
Structured Data 的价值是“帮系统理解内容的语义与实体关系”,不是排名因素。 添加 Schema 可提高系统理解深度,有助于启用部分 LLM 驱动特性(例如商家评分、FAQ 展示等)。 冗余的结构化数据只会拖慢加载、增加代码负担,不会有额外排名加权。 结构化数据需持续维护,过时或报错的数据可能导致你错过展示机会。 添加 Structured Data 并不保证触发富媒体结果,系统会根据上下文判断是否展示。
图片和视频是如何被索引的?
索引先从 HTML 开始,媒体内容另走一条异步管线处理。 若页面 HTML 已进索引,而图片/视频迟迟未出现在搜索中,很可能是因为媒体索引尚未完成,而非出错。 Google 不关心图片是否 AI 生成,只在意是否有效传达内容。

• 示例:大会首日展示中使用了一张 AI 图,虽然细节有误,但因为只是装饰道具,对排名无影响。
Geotargeting 如何影响内容选择?
• hreflang 是跨区域内容桥接的核心机制。 • 不需要为了避免重复而隐藏两个地区的相同页面,系统能识别这种结构。 • 但如果两个页面都没有本地化(只是换了域名),会让系统和用户都感到困惑。 • 地理定向不同于语言定向;两者信号机制不同,不能互相代替。 • 地域定向的信号来源包括:
• ccTLD(如 .sg 、 .au ) • hreflang 标注 • 服务器 IP 所在地 • 页面语言、币种、Business Profile、外链来源等区域信号

索引信号提取阶段
结构处理完成后,系统会提取各种直接与间接信号,包括:
• PageRank(内部依旧使用) • 页面关键词、语义位置 • 外链与提及(mentions)
PageRank 虽不是 1996 年原始算法,但依然以同名信号形式参与排序。
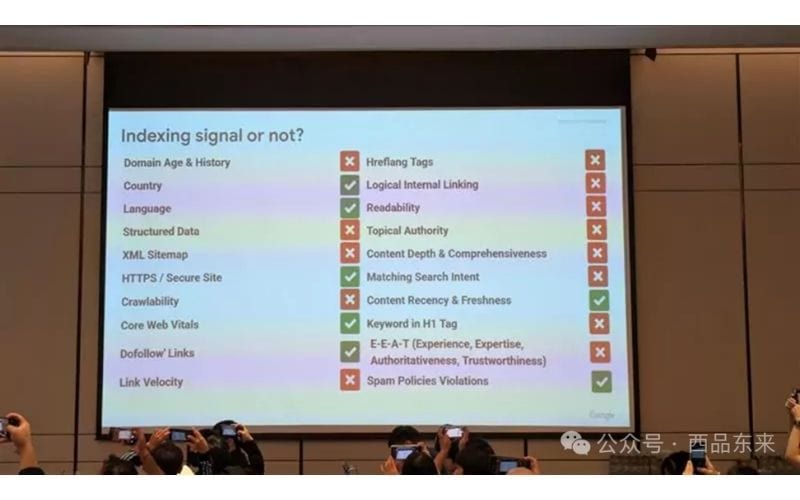
什么样的内容不会进索引?
- 有明确 noindex 指令的页面
- 活动过期页面(建议用
unavailable_after管理) - 内容极度稀薄、价值低(被标注为 soft 404)
- 明显重复的聚类副本
- 被 SpamBrain 判定为垃圾内容(Google 每天识别 400 亿页) !

违反政策的页面(如恶意下载、误导性标题等)
补充:Internal Linking 只能在页面已经“有一定价值”时起到辅助作用。本质上不是加了链接就能保住索引,而是链接让页面更有用,才得以保留。
E-E-A-T 是指标吗?
不是。E-E-A-T(Experience、Expertise、Authoritativeness、Trustworthiness)是 Quality Rater Guidelines 中的评价原则,而不是索引或排名的算法参数。
Google Trends API(Alpha)正式发布
由 Daniel Waisberg 与 Hadas Jacobi 联合发布:
- 支持连续对比的搜索兴趣指数,不因关键词变化而重新标定。
- 可查看 5 年滚动数据,延迟不超过 48 小时。
- 时间粒度可选:按周、月、年聚合。
- 可按地区和子地区维度分析。
- 为程序化趋势监测与跨时间对比打开了新路径。
Day 3:Serving(展现)
关键词:查询理解(qu ery understanding)、上下文同义词(contextual synonyms)、质量评估框架(E-E-A-T)、内容更新类型、结构化数据作用边界
一句话总结: Google 搜索的排序逻辑涵盖多种信号,其中“质量”是关键之一。衡量质量的核心,仍然回到一个标准:这份内容是否值得被用户信任。
一个常被忽视的事实: 就算没有结构化数据,Google 仍可能展示诸如站点名、面包屑等信息;页面结构与内容清晰度,常常比是否添加 Schema 更能影响系统对页面的理解。
查询理解机制
Google 的服务系统由查询理解、检索、索引选择、排序、特性应用(如富结果)五个阶段组成。

查询理解的首要环节,是对查询词的分割。对中文、日文等无空格语言,Google 会借助历史查询与文档进行分词学习(segmenting)。并不是所有语言都需要这一步。接着系统会移除停用词(stopwords),除非它们构成特定短语或实体(如《The Lord of the Rings》)。然后进入查询扩展阶段,会加入跨语言的同义词,用于更好理解用户真实意图。一个关键机制是上下文同义词(contextual synonyms): 例如,“car hire” 与 “rental car” 并非传统字典中的同义词,但在真实点击行为中被系统判定为“siblings”,在特定上下文中可互换。


这类语言理解与语义映射对用户不可见,但能显著提升召回相关信息的能力。
如何理解“质量”信号
Google 明确指出:排序信号有很多,“质量”是其中一个,但非常关键。搜索系统对“好内容”的定义聚焦五点:
- 以用户为中心(people-first)
- 专业性(expertise)
- 内容与质量(content and quality)
- 呈现与制作(presentation and production)
- 避免以搜索引擎为导向的内容(avoid search-engine-first)
这些维度来源于《质量评估员指南》(QRG),虽不直接参与排名计算,但用于衡量系统表现。 • 当 QRG 出现更新,代表 Google 对“好内容”的标准也在同步演进。

四大质量支柱
在 QRG 中,Google将“质量”细化为四个核心维度:
- Effort(投入):体现创作时间、技能、经验。
- Originality(原创性):包含独立研究、原创分析、不同视角。
- Talent or Skill(技能与表现力):可以不是权威专家,但必须呈现真实经验与扎实表达。
- Accuracy(准确性):基于证据,符合专业或公众共识。
E-E-A-T 框架与信任的优先级
从 E-E-A-T(Experience, Expertise, Authoritativeness, Trustworthiness)四个维度来看,“信任(Trust)”是最重要的。即使页面不涉及 YMYL(Your Money or Your Life)领域,Google 依然会优先展现更可信的内容。若页面观点明显违背主流专家共识,可能被判定为不可靠。
澄清一点:网站中出现大量 404 页面或使用 noindex 标签,不会影响“质量”评估。这些是技术层面信号,非质量问题。
谷歌搜索系统更新的三个原因
Google Search 的更新通常出于三个目的:
1. 支持新内容形式:如短视频、互动视觉等,如果用户需求上升,Google 可能上线新展现模块。 2. 提升内容相关性:通过核心算法更新,整体提升内容筛选的质量。这类更新不针对具体站点。 3. 打击低质量内容与 spam:调整系统识别策略,降低无价值或操纵型内容在搜索结果中的占比。

更新后的应对策略
核心更新不等同于“惩罚”,也不存在传统意义上的“恢复”。Google 建议站点:
- 保持高质量内容的创作;
- 学习表现更好的站点,理解其做得更好的地方。
- 对于垃圾内容更新(Spam Updates):
- 明确指出的问题,应按照官方博客指导进行整改与删除。
结构化数据的边界与误解
- 添加结构化数据(Schema)并不会直接影响排名。
- 在合适的情况下,它能增强结果展示形式,提高点击率,从而间接提升表现。
- 但添加 Schema 并不能保证展示富结果,是否触发由系统算法决定。
重点提醒:
- 即使不添加结构化数据,Google 也可能依靠页面语义结构,主动展示站点名称、面包屑等富元素。
- 正确的 HTML 构造与内容清晰度,常常比标注更具影响力。
- Schema 不是一次性工作,需定期检查与维护,确保数据准确、无报错,才能持续适配富结果特性。
全盘总结
三天大会,绕了一圈,最终都在回答同一个问题:
当内容的展现形式发生剧变时,Google 依然如何判断它是否“值得被看见”?
不管是 AI Overviews、结构化数据,还是 E-E-A-T 框架和多模态召回,本质都指向两个核心判断:
• 内容是不是为人写的 • 内容值不值得信任
这不是SEO的消亡,而是回到它最初该有的模样。

