对大多数做 GEO(Generative Engine Optimization,生成式引擎优化)的站点来说,优先级从高到低是这样的:
- Organization(品牌实体)、WebSite、WebPage、Article / BlogPosting、Person——这是 P0 级,任何站点都该有;
- FAQPage、Product + Offer、HowTo、Service / SoftwareApplication——这是 P1 级,按业务场景选做;
- BreadcrumbList、Review / AggregateRating——P2 级,锦上添花。
Google 在 2025 年 6 月已经 sunset 的 Book Actions、Course Info、Claim Review、Estimated Salary、Learning Video、Special Announcement、Vehicle Listing、Sitelinks Search Box 等类型,不必再投入资源。
下面讲为什么是这个清单,以及每一项具体怎么做、哪些坑要躲。
一、Schema 在 AI 搜索里的三个作用
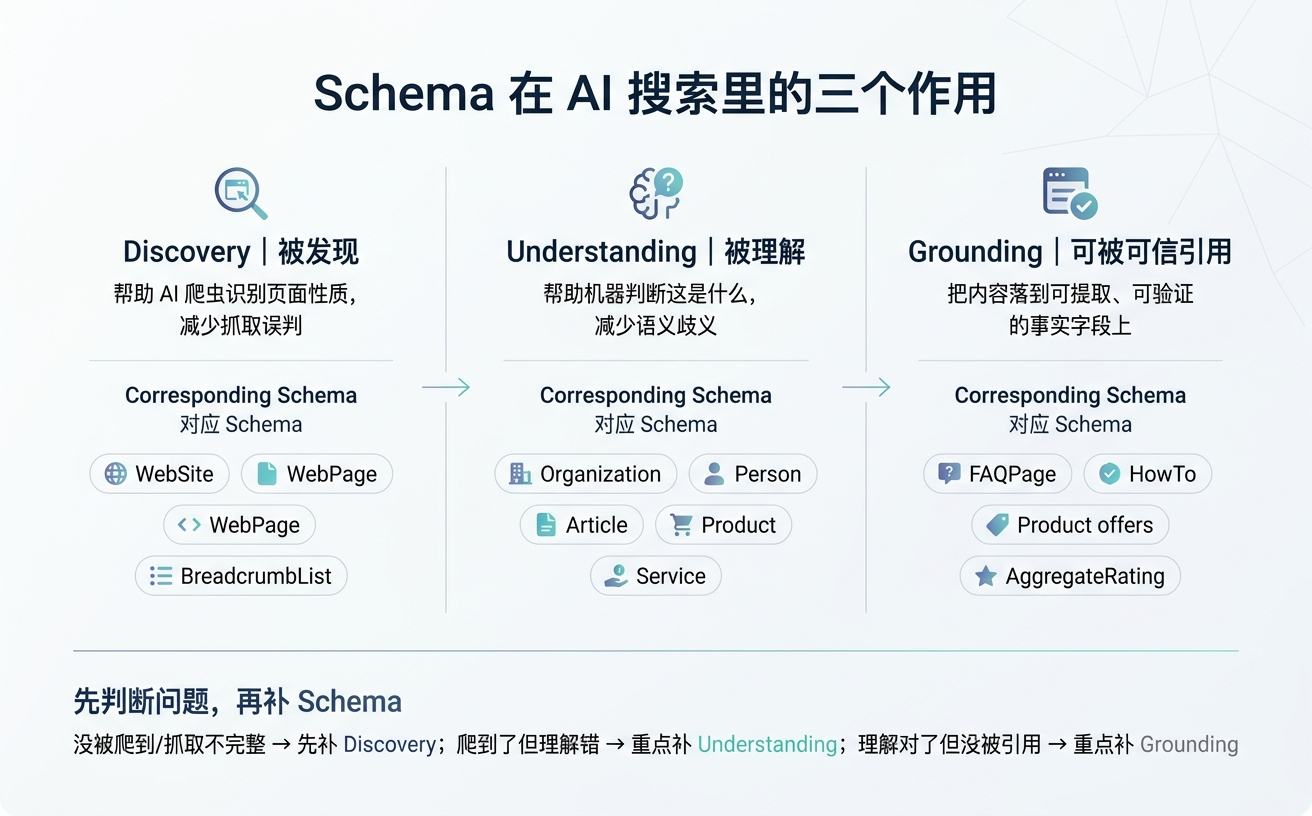
Schema 在生成式搜索里承担三件事,每一件对应一组类型。
被发现(Discovery):让 AI 爬虫在抓取阶段识别页面性质、减少误判。WebSite、WebPage、BreadcrumbList 属于这一层。
被理解(Understanding):消除歧义,告诉机器”这是产品不是评论””这是作者不是引用者””这是服务不是博客”。Organization、Person、Article、Product、Service 都在这一层。这一层是 schema 最不可替代的价值,纯语义化 HTML 做不到。
可被可信引用(Grounding):AI 在生成答案时需要把语言落到可提取、可验证的事实字段上。FAQPage 的 Q&A 对、Product 的 price 和 aggregateRating、HowTo 的步骤结构,都是给 AI 准备的”可摘录块”。
对照自己站点的问题:是没被爬到、是爬到但理解错了、还是理解对了但没被引用?三种情况对应的 schema 补法完全不同。
如果问题是没被爬到或爬取不完整,先补 Discovery 层——检查 WebSite、WebPage、BreadcrumbList 是否齐全,以及 sitemap.xml 和 robots.txt 是否放行了 AI 爬虫。
如果问题是爬到了但 AI 描述你的品牌/产品不准确,问题在 Understanding 层——重点补 Organization 的 sameAs 和 Product / Service 的核心属性。
如果问题是品牌描述对,但在对比/推荐类问题里不被选中,问题在 Grounding 层——补 FAQPage、HowTo、Product 的 aggregateRating 和 offers 等可提取字段,同时要回到内容本身检查是否足够被引用。
二、Schema 不是万能药
Reddit 几乎没有 schema 标记,却是 Google AI Overview 和 Perplexity 引用最密集的站点之一,AI Overview 引用量在 2025 年一个季度内增长约 4.5 倍。Search/Atlas 在 2024 年底的一份分析也显示,schema 覆盖度和 AI 引用率之间没有观察到稳定的相关性。
另一边,Microsoft Bing 的 Fabrice Canel 在 2025 年 3 月的 SMX Munich 上确认 Bing 的 LLM 会使用 schema 理解网页;Google 搜索团队也在 2025 年 4 月表态结构化数据在搜索结果中带来优势。
两组事实告诉我们:内容是否值得被引用,由专业度、第一人称经验(Experience)、数据密度和第三方背书决定,schema 救不了薄内容。但在内容处于”被选与不被选”边缘的时候,schema 会让机器更容易正确理解你、更容易把你当作可引用的事实源。这是加速作用,不是决定作用。
三、做GEO 需要哪些 Schema?
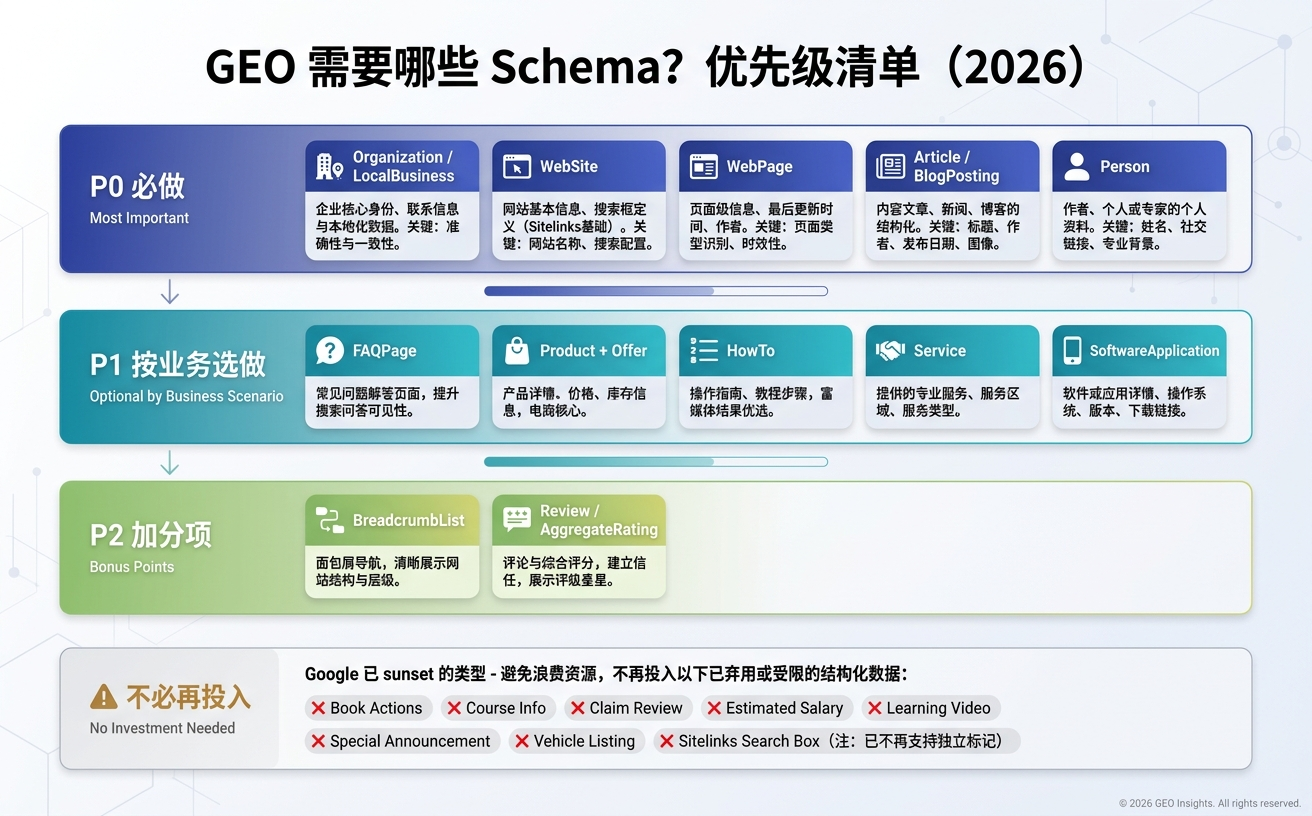
P0 级:任何 GEO 站点都该有的基础
Organization(或 LocalBusiness) 是品牌实体锚点,也是全站 schema 体系的起点。关键不在”填了”,而在 sameAs 属性是否把站点连回了 Wikipedia、Wikidata、LinkedIn、官方社交账号——这是 AI 判断品牌是否真实存在、是否可信的核心信号。一段最小可用的示例:
json
{
“@context”: “https://schema.org”,
“@type”: “Organization”,
“@id”: “https://yourdomain.com/#organization”,
“name”: “Your Brand Name”,
“url”: “https://yourdomain.com”,
“logo”: “https://yourdomain.com/logo.png”,
“sameAs”: [
“https://www.linkedin.com/company/yourbrand”,
“https://www.wikidata.org/wiki/Qxxxxx”,
“https://en.wikipedia.org/wiki/Your_Brand”
]
}
注意 @id 写成一个全站唯一的 URI,后面其他 schema 会用它引用这一实体。
WebSite 和 WebPage 定义全站与单页的语义边界。WebSite 放站点首页,WebPage 放每个具体页面,两者通过 isPartOf 连接。
Article 或 BlogPosting 处理内容归属。必填 author(嵌套 Person 类型)、datePublished、dateModified。AI 判断内容时效性高度依赖这两个日期字段,缺一个都会被判为”时效不明”。author 不要填品牌名,要填真实作者,并关联到 P0 级的 Person 实体。一段示例,注意 author 和 publisher 都用 @id 引用到前面定义过的实体:
json
{
“@context”: “https://schema.org”,
“@type”: “Article”,
“@id”: “https://yourdomain.com/blog/geo-schema-guide/#article”,
“headline”: “GEO 需要哪些 Schema?一份优先级清单”,
“datePublished”: “2026-04-17”,
“dateModified”: “2026-04-17”,
“author”: {
“@type”: “Person”,
“@id”: “https://yourdomain.com/team/author-name/#person”
},
“publisher”: {
“@id”: “https://yourdomain.com/#organization”
},
“mainEntityOfPage”: {
“@id”: “https://yourdomain.com/blog/geo-schema-guide/#webpage”
}
}
publisher 这里没有重复写一遍 Organization 的内容,只引用 @id——这是正确做法。整站只应该有一份 Organization 的完整定义,其他地方一律用 @id 指回去。这样 AI 抓取到的才是一张连通的实体图,而不是重复、可能互相冲突的多份副本。
Person 承载 E-E-A-T 里的 Expertise 和 Authoritativeness。作者页、团队页、About 页要用。重要属性是 jobTitle、worksFor(指向 Organization 的 @id)、sameAs(作者本人的 LinkedIn、学术主页等)。一段示例:
json
{
“@context”: “https://schema.org”,
“@type”: “Person”,
“@id”: “https://yourdomain.com/team/author-name/#person”,
“name”: “Author Name”,
“jobTitle”: “Senior GEO Strategist”,
“worksFor”: {
“@id”: “https://yourdomain.com/#organization”
},
“sameAs”: [
“https://www.linkedin.com/in/authorname”,
“https://scholar.google.com/citations?user=xxx”
]
}
把 Organization、Article、Person 三段组合起来看:一篇博客文章(Article)由一个作者(Person)撰写、由一个品牌(Organization)发布,作者服务于这个品牌——这些关系全部通过 @id 相互引用,而不是每次重复写完整信息。AI 抓到任何一段,都能顺着 @id 导航到其他两段,最终在模型的语义空间里把这三个实体稳定地关联起来。这就是实体图(Entity Graph)的雏形。P0 级的核心价值不在于各自的字段,而在于三者之间的这种连接。
P1 级:按业务场景选做
FAQPage 适合 Q&A 结构明显的页面,能直接对应 AI 答案的输出格式。这里需要澄清一个常见误解:Google 在 2023 年 8 月收窄了 FAQ 富媒体结果的展示范围,只对政府和健康权威站点保留,很多团队因此停掉了 FAQ schema——这是错的。富媒体展现收窄不等于 AI 不再读取,FAQ schema 提供的”问题—答案”配对结构,对生成式搜索拼装答案仍然有直接价值。加它的理由从”搜索结果里多一栏”变成了”AI 更容易把你的答案摘出来”。
Product + Offer + AggregateRating 是电商和 SaaS 产品页的标配。常见问题是属性填得过少:name 和 price 之外,brand、sku、image、offers.availability、offers.priceCurrency、aggregateRating.ratingValue、aggregateRating.reviewCount 都是决定 AI 是否拿你的产品进推荐候选集的字段。缺一个,AI 在对比答案里选中你的概率就低一档。
HowTo 适用于步骤型教程。和 FAQ 情况类似,Google 对它的富媒体展现已经收窄,但 AI 在回答”如何做 X”类问题时仍然会参考 HowTo 的步骤结构,值得对真正的步骤型内容继续使用——注意是”真正的步骤型”,不要把普通文章硬套 HowTo。
Service 或 SoftwareApplication 对应服务型业务和 SaaS 产品。它们和 Product 的区别在于:Product 默认描述实体商品,很多属性(sku、gtin、mpn)对服务不适用;Service 提供 serviceType、areaServed、provider、hasOfferCatalog 等更贴合服务业务的字段,SoftwareApplication 则有 applicationCategory、operatingSystem、offers 等 SaaS 专用属性。用错类型会导致 AI 把 SaaS 产品识别成实体商品,在推荐逻辑里归错类。
P2 级与不建议做的
BreadcrumbList 辅助层级理解,Review 和独立 AggregateRating 增加社交证明,优先级低于前两档,有精力再做。
不建议投入的类型有两组。
一组是 Google 2025 年 6 月已 sunset 的:Book Actions、Course Info、Claim Review、Estimated Salary、Learning Video、Special Announcement、Vehicle Listing、Sitelinks Search Box。
另一组是对应内容用户看不见的 schema——比如页面上没有的评分、没有的 FAQ 条目、没有出现的作者。schema.org 官方和 Google 官方都将其视为作弊,代价是整站级富媒体降权。
四、工程化落地的三个关键点
1. 属性填写完整度比类型数量重要
schema.org 目前定义了 806 种类型、1400 多个属性。真正拉开站点差距的是关键属性的完整度,不是用了几种类型。Product 有 20 多个属性,大多数站点只填了 name 和 price,其他全空——这种情况下加 10 种 schema 也不如把一个 Product 填齐。
可行的做法是为每一个核心类型建一份”必填 + 推荐填”属性清单,作为内容团队和开发团队的对接标准,不交给 CMS 插件的默认值。以 Product 为例,一份用得上的清单大致长这样:
- 必填(缺失就别上线):name、image、description、brand(引用 Organization 的 @id)、sku、offers(包含 price、priceCurrency、availability、url)。
- 推荐填(决定 AI 是否选你):aggregateRating(包含 ratingValue 和 reviewCount)、review(至少 1-3 条真实评价)、gtin 或 mpn(实体商品)、category、material / color / size(按品类相关字段)。
- 按需填:hasMerchantReturnPolicy、shippingDetails(谷歌购物相关)、isRelatedTo(产品关联,有助于 AI 理解产品矩阵)。
每一种核心类型都整理一份类似的清单,把它作为发布前的自检项。属性填不齐的页面不上线,比上线一堆半成品 schema 更有价值。
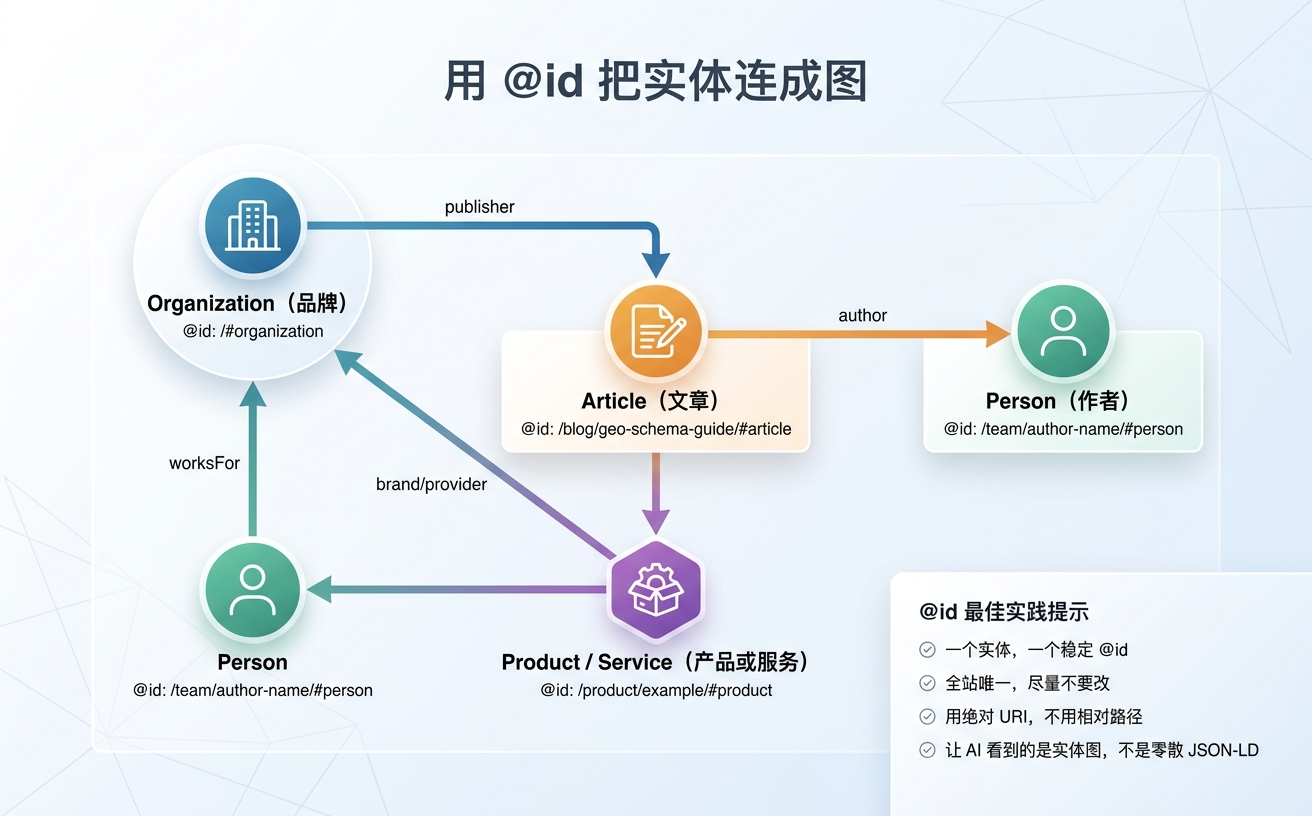
2. 用 @id 把实体连成图
大多数团队的做法是每个页面独立加一段 JSON-LD,彼此之间没有引用关系。AI 看到的就是一堆零散节点。
正确做法:给每一个实体——品牌、作者、产品——分配一个全站唯一的 URI 作为 @id,然后在 Article.author、Article.publisher、Product.brand 这些字段里用 @id 相互引用。这样 AI 看到的不再是零散标签,而是一张可导航的实体图(Entity Graph)。这是实体对齐(Entity Alignment)的基础,也是让 AI 稳定识别品牌身份的技术前提。
@id 的命名有几条简单规则。一是用完整的绝对 URI,不用相对路径。二是格式通常是 https://yourdomain.com/path/#type,#type 部分表明这是什么实体(如 #organization、#person、#article、#product)。三是一个实体一个 @id,全站唯一且稳定——Organization 全站只有一个 @id,不论它出现在多少页面上,引用的都是同一个 URI;作者 A 的 Person @id 也只有一个,不要每篇文章都为同一个作者生成一个新 URI。四是**@id 一旦确定就不要改**,改了相当于在 AI 的认知里重置了这个实体。
3. 核心页面的 schema 不要依赖前端 JS 注入
根据目前公开信息,ChatGPT-User 等部分 AI 爬虫倾向于处理静态 HTML,通过 JavaScript 在客户端动态写入的 JSON-LD 不一定能被识别。Google 的 Rich Results Test 能渲染 JS 并验证成功,但不代表所有生成式搜索的爬取管线都有同等能力。
核心页面的 schema 一律服务端渲染、直接写进 HTML,不依赖前端 JS 注入。WordPress、Shopify 等主流 CMS 默认就是服务端渲染,schema 插件输出的 JSON-LD 会直接进 HTML,这种情况下不用特别处理;真正需要注意的是 React、Vue 等单页应用(SPA)架构——如果用这类技术栈,必须确认 schema 是通过服务端渲染(SSR)或静态生成(SSG)方式写入,而不是等页面加载后由客户端 JavaScript 注入。
五、验证与常见风险
Schema 上线前后要分阶段验证,用不同的工具看不同的东西。
上线前:Google Rich Results Test(search.google.com/test/rich-results)。把页面 URL 或 JSON-LD 代码片段直接粘进去,它会告诉你三件事:Google 是否能解析这段 schema、是否有必填字段缺失、是否有字段格式错误。重点看”Warnings”和”Errors”——Errors 必须清零,Warnings 按优先级处理。这个工具只检查 Google 支持的富媒体类型,不覆盖 schema.org 全部类型。
上线前:Schema.org Validator(validator.schema.org)。这个工具更严格,按 schema.org 官方规范检查所有类型和属性,包括 Google Rich Results Test 不覆盖的。两个工具配合用:Rich Results Test 看”Google 能不能用”,Schema.org Validator 看”是否符合官方规范”。两者都通过再上线。
上线后:Google Search Console 的”增强功能”报告。进入 Search Console → 左侧菜单”Enhancements”(增强功能),里面会按 schema 类型分别展示状态:Valid(有效)、Valid with warnings(有效但有警告)、Error(错误)。每周至少看一次,尤其是发布新页面或批量修改模板后。错误量突然上涨通常意味着模板改动引入了问题,要立刻排查。
上线后:在实际 AI 搜索里抽查。验证工具能确认 schema 语法正确,但不能确认 AI 真的读到了。方法是:在 ChatGPT、Perplexity、Google AI Overview 里搜几个与你业务相关的真实问题,观察返回答案里品牌信息(名称、作者、产品参数)是否正确、完整。如果 AI 的描述和你 schema 里填的内容一致,说明信号传递到位;如果描述模糊或错误,说明 schema 之外还有问题,或者这个爬取路径没用到 schema。
有三个风险需要提前知道。
- 第一,必填字段缺失会导致整段 schema 被 Google 忽略,等同于没做——这也是 Rich Results Test 的 Errors 要清零的原因。
- 第二,错误信息——假评分、假价格、与页面不符的作者——会触发整站级富媒体降权,恢复需要走正式申诉,周期通常以月计。
- 第三,直接用 LLM 生成 schema 后不审核就上线风险很高:Semantic Web Journal 发表的一项研究(Dang et al., 2025)显示,缺乏人工审查流程的 LLM 生成 schema 有约 40–50% 存在无效、幻觉或不合规问题。AI 工具可以加速生成,但不能取代人工字段核对。
结语
Schema 不会单独带来 AI 引用,但没有它,其他层的 GEO 优化工作常常事倍功半。把 P0 做齐、把 @id 连起来、把属性填完整——这三步做到位,前面的清单才开始真正发挥作用。
如果你不确定 schema 到底是不是你当前站点的瓶颈,可以和西品东来先聊一次。我们会先看你的站点目前处在哪一层——是还没被 AI 爬到、是爬到但理解错了,还是理解对但没被引用——再判断 schema 是不是此刻该投入的事。如果不是,我们会直接说,并告诉你真正的瓶颈在哪里。