先把读者最想知道的五个问题一次说完。
Wikipedia 实体建设是什么? 狭义讲,指给品牌在 Wikipedia 上建条目,让 AI 在回答关于你品牌的问题时,把你当作一个有事实背书的实体来引用。但实际做起来会发现还有一个东西叫 Wikidata——它是 Wikipedia 背后的机器可读结构化数据库,同属 Wikimedia 基金会旗下,但规则、门槛、对 AI 的作用路径完全不同。很多人搜 Wikipedia 实体建设的时候没意识到这一点,结果把路径走错了。所以下面的判断会把两者分开讲。
做了对你的 GEO 有什么好处? Wikipedia 是 ChatGPT 引用最多的单一域名(Semrush 2025 年研究),并且约占 GPT-3 训练数据的 3%,是所有主流 LLM 预训练阶段的重要语料来源之一。有 Wikipedia 条目的品牌,AI 对你的描述通常更准确、更稳定;没有条目的品牌,AI 只能从零散来源拼凑认知。Wikidata 则直接被 Google Knowledge Graph、Siri、Alexa、Copilot 等系统查询,是 AI 做实体消歧(”你是哪个 Apple——水果、公司,还是唱片公司?”)的核心依据。
不做对你有什么坏处? 没有 Wikipedia 条目的品牌不会”失败”——Wikipedia 对 AI 引用的影响主要集中在认知阶段查询(”XX 品牌是什么””XX 品类包括哪些公司”),在决策阶段查询里权重不高。没有 Wikidata 条目的品牌也不一定 AI 可见性就差——AI 认知品牌还有其他路径(独立媒体报道、官网 schema、评测站、社区讨论等),Wikidata 只是其中一条高杠杆路径,不是唯一必经之路。
你应该做还是不做? 分两档判断。Wikidata 是一个成本低、几乎无风险的基础动作,值得优先考虑——没有 notability 门槛、两小时内能建完、立刻机器可读。做了有稳定收益,没做也不等于 GEO 一定有问题。Wikipedia 条目则大多数 B2B / SaaS 品牌暂时不该做——要么还不够 notability 资格、做了会被删;要么就算做成,带来的 AI 引用提升不如把同样的时间花在自有内容和垂直媒体上。
不做 Wikipedia 行不行? 完全行。Search Engine Land 2025 年 10 月发表的一份行业分析中提到,在一次针对 300 多个 B2B SaaS 高购买意图提示词的追踪实验里,Wikipedia 几乎没有出现在引用列表中,AI 引用的主力是垂直评测站、行业博客和品牌官网。Wikipedia 对”什么是 X 类目”这种认知阶段查询权重高,对”选哪家”这种决策阶段查询权重很低。
下面把这几个判断的来龙去脉、该做的时候怎么做、不该做的时候做了什么后果,一条条讲清楚。
一、Wikipedia 和 Wikidata:同生态,两件事

这两者都属于 Wikimedia 基金会旗下,但不是同一个产品。它们对 AI 的作用路径不同,要做哪一层的门槛也不同。把它们混为一谈,是很多团队做错路径的根源。
Wikipedia:人读的散文条目
Wikipedia 是散文条目,给人阅读。它进入所有主流 LLM 的预训练语料——OpenAI 和 Wikimedia 基金会之间还有正式的数据许可协议——这意味着模型对你品牌的”底层认知”很大程度上由 Wikipedia 上关于你的内容形成。但它的门槛极高:需要独立、可靠、多样的来源中的显著报道(notability 标准),并且由严格的 COI(Conflict of Interest,利益冲突)规则管控——你、你的员工、你的 PR 团队、你雇的 agency 都不能直接编辑与自己相关的条目。
值得澄清一个常见误解:Wikipedia 链接是 nofollow 的,不传递传统意义上的 SEO 链接权重。做 Wikipedia 条目不是为了反向链接,是为了 AI 对你的事实性理解和品牌可信度。
Wikidata:机器读的结构化数据
Wikidata 是机器可读的结构化数据库。每个实体分配一个 Q 号(Q identifier),属性以字段形式存储——名称、成立时间、总部、行业、官网、权威标识符(GND、VIAF、ISNI 等)。建完后立即被 Google Knowledge Graph、Apple Siri、Amazon Alexa、Microsoft Copilot 等系统查询。没有 notability 门槛——任何可被独立来源验证的实体都能建。
一句话区分:Wikipedia 影响 AI 对你品牌”说什么”,Wikidata 影响 AI 对你品牌”识别得对不对”。前者关乎描述质量,后者关乎实体消歧。前者门槛高、失败风险大;后者门槛低、做就有收益。
二、为什么大多数品牌不该冲 Wikipedia
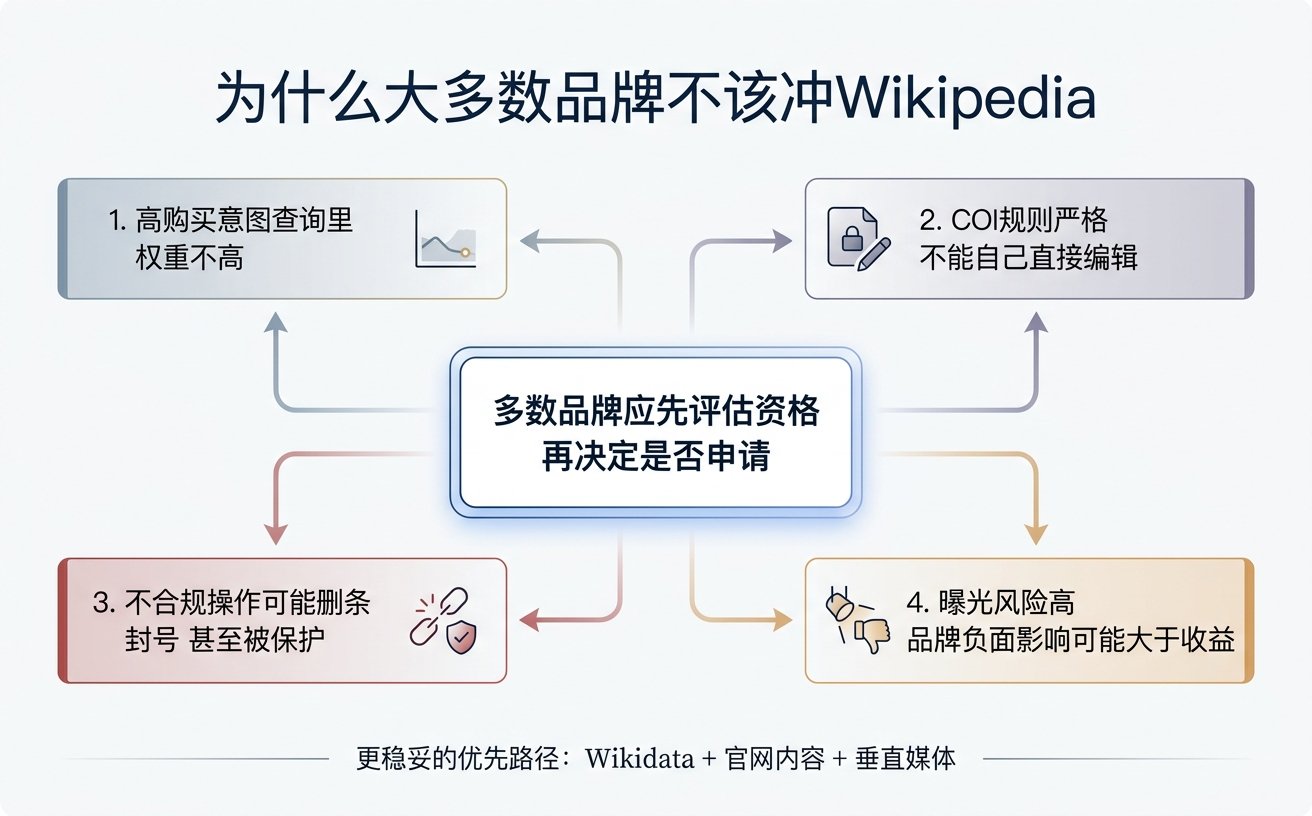
第一个原因:宏观统计数据会误导人。Reddit 和 Wikipedia 在 AI 引用中占统治地位的事实是真的,但这是因为它们话题覆盖面极广(Wikipedia 有超过 680 万条英文条目,Reddit 几乎每个话题都有子版块)。当你把分析范围缩小到业务真正关心的高购买意图查询——”哪个 CRM 适合 50 人团队”、”项目管理工具怎么选”、”物流软件哪个好”——Wikipedia 的实际引用率大幅下降。Search Engine Land 2025 年 10 月的分析报道了一个实验:针对 300 多个 B2B SaaS 高意图提示词的追踪中,Wikipedia 几乎没有在 AI 回答的引用列表里出现,主力引用源是垂直评测站、行业博客、品牌官网。
第二个原因:COI 规则是硬门槛。和条目主题存在财务、雇佣、代理、亲属关系的人都不应该直接编辑该条目。违反这条规则最常见的结果是条目被挂模板、被删除、账号被封。更严重的是 Salting——反复不合规建立尝试,可能导致 Wikipedia 管理员把该条目标题加入保护列表,从此无法再以该名创建条目。一旦触发,品牌基本失去”原名 Wikipedia 条目”这个资产。
第三个原因:公开曝光的品牌风险。Wikipedia 所有编辑记录永久公开可查。普林斯顿大学研究过用 AI 批量生成推广词条的行为,编辑团队几乎立刻识别并删除,账号被封。r/hailcorporate 等社区专门追踪并曝光品牌在 Wikipedia 上的不当行为。2011 年 Bell Pottinger 公关公司替客户操纵 Wikipedia 被英国媒体大规模曝光,是一个经典案例。不合规编辑一旦被发现,品牌损失远超当初通过编辑想获得的收益。
第四个原因:高意图查询里 Wikipedia 权重本就不高。AI 在回答”XX 是什么品牌”这种认知阶段问题时会优先引用 Wikipedia;但在回答”我该选哪家”这种决策阶段问题时,引用的主要是产品官网、对比评测、行业社区讨论。B2B 和 SaaS 的核心转化发生在决策阶段——这恰恰是 Wikipedia 帮不上忙的地方。
对绝大多数成长期 B2B / SaaS 品牌,把想冲 Wikipedia 的精力花在 Wikidata + 自有官网深度内容 + 垂直媒体第三方语境,收益会明显更高。
三、什么情况下 Wikipedia 条目确实值得做

已经具备 notability 的品牌。独立媒体在过去 12–24 个月内有至少 3–5 篇实质性原创报道(不是新闻稿转载),且覆盖多个权威来源。判断方法:用 Google 搜品牌名,排除自家域名和转载,看独立深度报道数量。一个行业内的共识是——普通初创公司拿不到 Wikipedia 条目很正常,是 notability 门槛过不去,不是方法问题。
C 端、消费品、知名品牌。AI 在回答”XX 是什么品牌”的消费类问题时,Wikipedia 权重远高于 B2B 场景。面向大众消费者的品牌,Wikipedia 条目带来的认知层 AI 引用值得投入。
创始人或高管本身有独立 notability 的情况。很多做过的人的共识是:创始人 Person 条目比公司 Organization 条目更容易通过——因为人物 notability 有时候通过学术成就、公开演讲、媒体访谈积累起来,相对独立于公司的商业曝光。这种情况下优先做创始人条目,同样对 AI 认知品牌有帮助。
需要反向修正已有错误描述的情况。如果 AI 已经在用错误信息描述你的品牌,且能追溯到 Wikipedia 上某个已存在条目(或某个提及),这时候必须通过合规流程推动修正——不是为了”建新条目”,是为了”修已有错误”。这一类必做,拖延代价更大。
合规申请条目的三步路径
如果你属于以上任何一类,合规的三步路径是这样:
第一步,先完成 Wikidata。把基础实体层站稳,并和官网 schema 里的 Organization 通过 sameAs 打通。
第二步,用个人账号在 Talk page 提建议,并公开披露 COI。标准披露模板:「我受雇于 XX 公司,不会直接编辑与雇主相关的条目,只会在 Talk page 用 {{request edit}} 提出建议,并提供独立可靠来源。我按 Wikipedia 的 COI 和付费编辑披露规则声明这一关联。」
第三步,等志愿者编辑审阅。请求不一定会过、最终措辞也可能不是你想要的。接受这两个现实,不要硬推、不要编辑战、不要用多个账号反复提交。
四、Wikidata 怎么做:低成本、低风险的基础动作
Wikidata 的价值不在于”非做不可”,而在于”做了几乎没有风险、可能带来稳定收益”。
需要填的核心字段
核心字段包括:官方名称(含多语言 label)、简短描述(description)、成立时间(inception)、总部所在地(headquartered in)、行业分类(industry)、官网 URL、Logo 图片、以及权威标识符——GND(德国国家图书馆权威档案)、VIAF(国际虚拟权威档案)、ISNI(国际标准名称标识符)。
这些标识符是把你的品牌连到全球知识图谱的关键,添加后多语言场景下 AI 对你的识别准确率会明显提高。普林斯顿大学与 IIT Delhi 在 2024 年 ACM KDD 会议上发表的 GEO 研究也印证了一个类似原则:结构化数据和权威引用对 AI 引用概率有稳定的正向影响,最高提升可达约 40%。
和官网 schema 的打通
Wikidata 条目建好后,把它的 URL 加入官网 Organization schema 的 sameAs 属性里。这样就在站内结构化数据和站外权威实体系统之间建立了引用关系,AI 判断品牌身份时有更强的信号可用。
COI 披露:Wikidata 的门槛宽松得多
COI 披露在 Wikidata 同样适用,但执行宽松很多。结构化数据本身不存在措辞偏见,编辑历史又容易审计,利益相关者只要公开披露身份、严格填事实、来源可验证,通常不会遇到删除。这是 Wikidata 相比 Wikipedia 最实际的门槛差异。
维护节奏
Wikidata 是活资产,产品改名、总部搬迁、高管更换、核心指标变化都要同步更新。建议每季度做一次全量字段核查。
五、你现在在哪一步:一个快速自测
三个动作,五分钟内完成。先看 AI 的实际回答,再用搜索结果和 Wikidata 反查原因。
第一步,也是最重要的一步——在 ChatGPT、Perplexity、Google AI Overview 分别问”XXX 品牌是做什么的”。回答准确、完整、跨平台一致 = 实体层在运作,不用急着补 Wikidata 或 Wikipedia,把资源投到其他 GEO 优化动作上更值。回答模糊、有错误、或者三个 AI 给出相互矛盾的描述 = 实体层有问题,下面两个动作帮你判断问题出在哪。
第二步,在 Google 搜品牌名,看右侧出现什么面板。带 Wikipedia 摘要、成立时间、创始人、”People also search for”这种字段的品牌 Knowledge Panel = Google Knowledge Graph 已识别你、实体层有支撑。
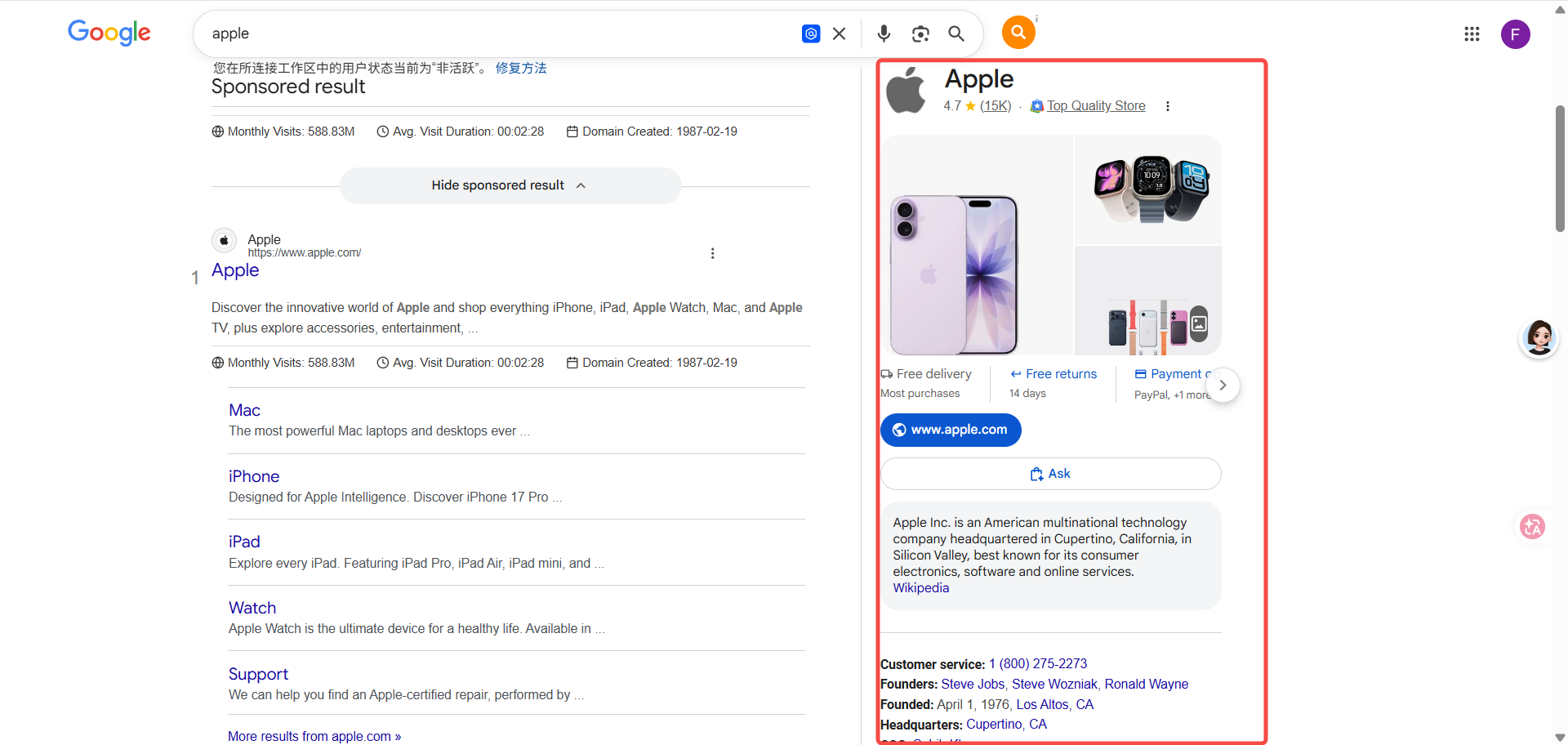
Knowledge Panel
只有商品图、店铺信息、配送/退货这种 Merchant Panel(Shopify 独立站、D2C 品牌常见这种)= Google 的电商系统知道你,但品牌实体识别还没建立。什么都没有 = 最底层的识别还没建。这一步是辅助参考,主要帮你判断问题出在”Google 有没有识别你”这一层。
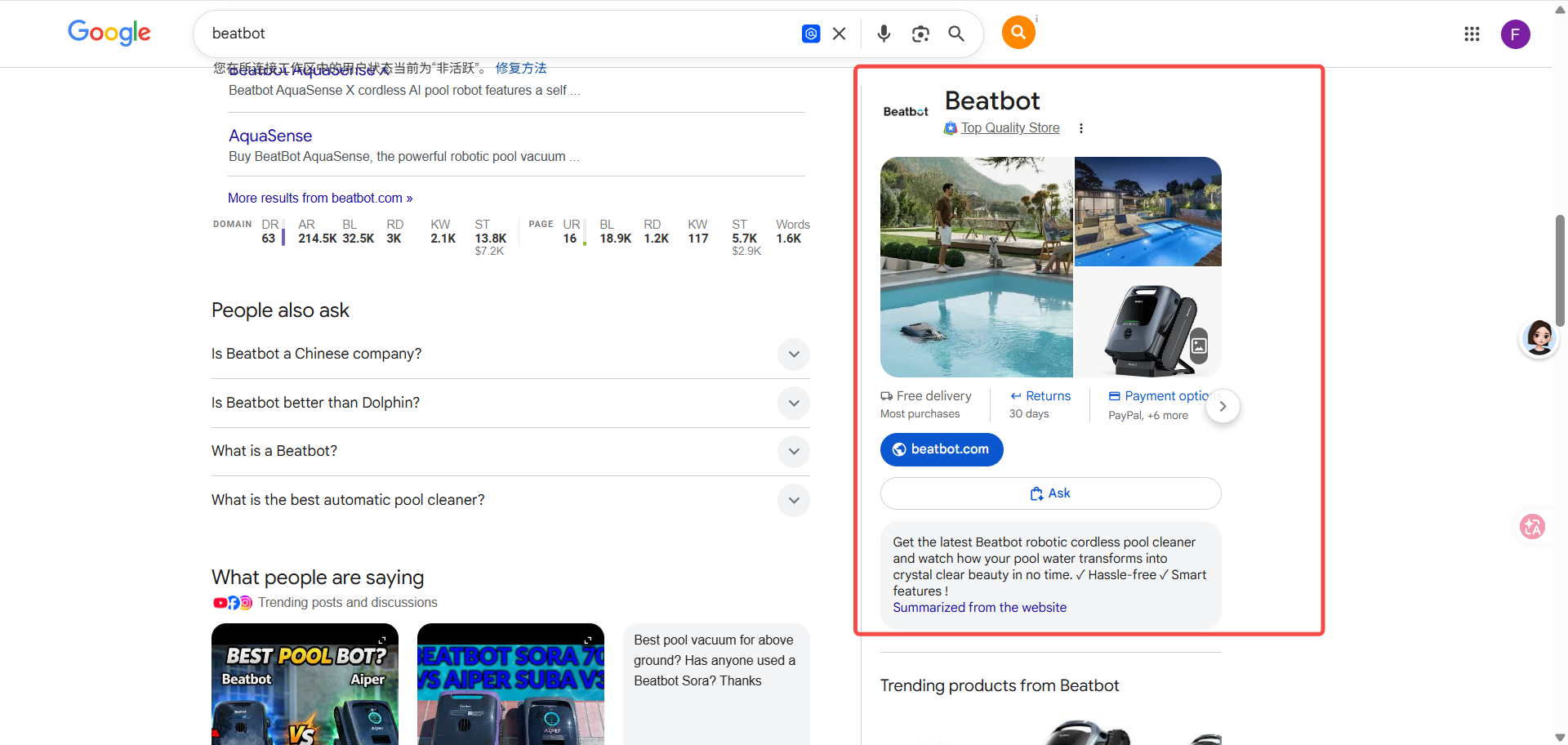
Merchant Panel
第三步,在 wikidata.org 搜品牌名。有条目 = 核查 Q 号下字段是否完整、是否包含权威标识符。无条目 = 如果前面两步已经显示 AI 描述不准确,那补 Wikidata 会是一个性价比很高的动作;如果 AI 描述已经准确了,Wikidata 可以做、也可以暂时不做,不是必需。
“维基百科实体建设”经常被讲成一个必须抓紧做的动作——这个说法害了不少团队。它其实更接近于”够资格再做、不够资格先别做”,跟企业阶段、媒体积累、品类特性都有关。在 Wikipedia 这件事上冒险不合规地冲,代价大多数时候远大于收益,先攒 notability 再合规申请是更现实的路径。