一个做户外装备的品牌,去年因为 Cloudflare 默认屏蔽规则把所有 AI 爬虫挡在门外,整整 8 个月在 ChatGPT 答案里完全消失。等他们发现的时候,三个主要竞品已经吃下了“露营装备推荐”这个词的全部 AI 引用位。
AI 时代配置 robots.txt 的核心原则是按爬虫用途分别授权:检索类爬虫(OAI-SearchBot、Claude-SearchBot、PerplexityBot)放行,以获得 AI 答案引用;训练类爬虫(GPTBot、ClaudeBot、Google-Extended)是否放行,要看内容是不是你的产品;敏感内容不能依赖 robots.txt,要用登录和权限保护。
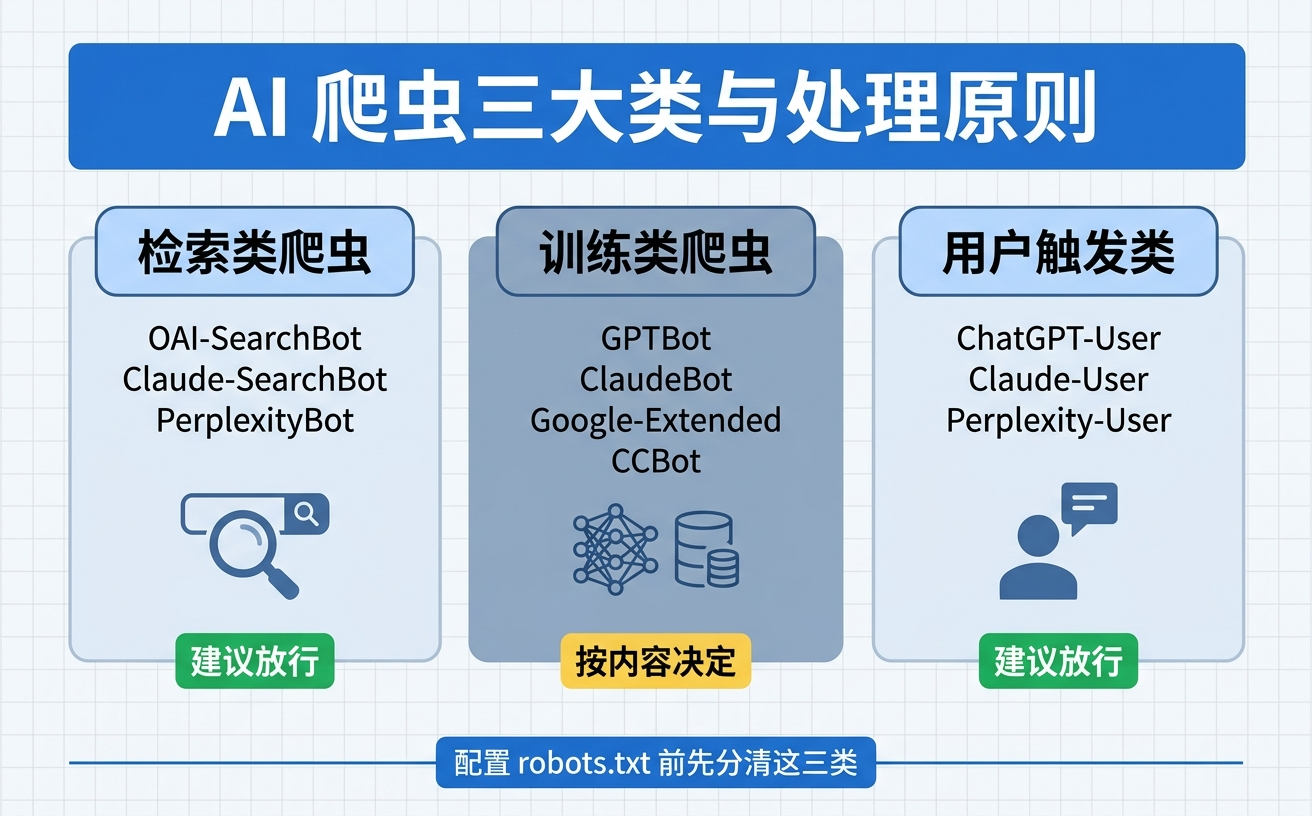
AI 爬虫三大类与处理原则速查图
robots.txt 配置模板:3 套可直接复制(按业务类型)
下面三套模板覆盖了常见网站类型,可以先选一套,再根据业务、版权和合规要求微调。
模板 A:B2B、SaaS、电商,最大化 AI 可见度
适合靠流量和品牌曝光赚钱的网站。放行所有主流 AI 爬虫,只屏蔽 admin、checkout、内部搜索这类噪音路径。
# 模板 A: 获客型网站基础配置
# 适用: B2B、SaaS、电商、品牌、本地服务
# 目标: 最大化 AI 可见度
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /checkout/
Disallow: /cart/
Disallow: /search?
Disallow: /*?utm_
User-agent: Googlebot
Allow: /
# AI 检索类爬虫,全部放行
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
# AI 训练类爬虫,也放行
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: CCBot
Allow: /
Sitemap: https://www.example.com/sitemap.xml
模板 A 放行训练爬虫是有原因的。对获客型网站来说,训练数据是免费的长期品牌投资——产品名、服务范围、差异化卖点进入模型后,未来一两年里 AI 每次相关回答都可能提到你,不需要再付任何成本。
比如一家泳池清洁公司,希望用户问“附近哪家公司可以做泳池维护”时,AI 能读到它的服务页、区域页和 FAQ。屏蔽 AI 搜索类爬虫,等于减少被推荐的机会。
模板 A 的两种变体
你的目标 | 建议做法 |
最大化 AI 可见度 | 检索类和训练类都放行(如上) |
只要 AI 搜索曝光,不想开放训练 | 放行检索类,把 GPTBot、ClaudeBot、Google-Extended 改成 Disallow |
不确定怎么选 | 先放行检索类,观察品牌提及情况 |
放行检索类爬虫不等于一定会被引用。它只是让 AI 搜索系统有机会访问你的页面。最终是否被提及,还取决于页面内容、问题匹配度、品牌实体信息和外部信号。
模板 B:媒体、博客、教程站,放检索挡训练
适合内容本身就是产品的网站。放行检索类爬虫保留 AI 答案里的引用回链,屏蔽训练类爬虫不让 AI 白嫖。
# 模板 B: 区分搜索和训练
# 适用: 媒体、内容站、Publisher
# 目标: 保留 AI 引用引流,防止内容被白嫖训练
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /wp-admin/
User-agent: Googlebot
Allow: /
# AI 检索类爬虫,放行
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
# AI 训练类爬虫,屏蔽
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Sitemap: https://www.example.com/sitemap.xml
《纽约时报》、Reuters、《卫报》等头部媒体陆续采用了这个组合策略——既避免内容被白嫖训练,又保留在 ChatGPT 搜索答案里的引用位。
模板 C:付费墙、会员站,保守屏蔽
适合付费内容、内部资料、敏感数据、法律或医疗等高合规压力网站。
前置提醒:robots.txt 不是安全工具。它只能表达抓取偏好,不能真正保护私密内容。真正敏感的内容应使用登录权限、服务器鉴权、IP 限制或私有存储。
# 模板 C: 付费内容 / 会员资料 / 敏感信息
# 目标: 减少 AI 抓取和公开引用风险
User-agent: *
Disallow: /members/
Disallow: /private/
Disallow: /internal/
Disallow: /paid-content/
User-agent: Googlebot
Allow: /
Disallow: /members/
Disallow: /private/
Disallow: /internal/
Disallow: /paid-content/
# 屏蔽主要 AI 检索类爬虫
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
# 屏蔽主要 AI 训练类爬虫
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Sitemap: https://www.example.com/sitemap.xml
选模板 C 要接受一个结果:网站在部分 AI 搜索答案中的可见度会下降。
如果你只想保护部分付费内容,不要全站屏蔽。更稳妥的做法是只屏蔽会员目录、下载目录、内部资料目录,保留公开服务页、品牌页、产品页和博客页。这样既能保护敏感内容,也不会完全切断 AI 搜索入口。
怎么判断我的网站该用哪套 robots.txt 模板?
一个简单的判断:如果明天你的网站完全停掉博客和文章,但产品还能卖、业务还能跑——选模板 A。如果停了博客就没饭吃,内容本身就是产品——选模板 B。
混合型情况,比如做家居用品的 Shopify 站,博客是为了带流量到产品页——这种情况内容是营销资产,不是商品本身,选模板 A。
有付费内容或敏感资料的,单独看模板 C,但要配合权限控制使用。
你的情况 | 建议模板 |
企业官网、B2B、SaaS、电商、品牌、本地服务 | A |
媒体、内容站、专业博客、教程站 | B |
付费内容、会员站、内部资料 | C + 权限控制 |
只有部分内容敏感 | A 或 B,只屏蔽敏感目录 |
不确定是否被 AI 提及 | 先做 prompts 追踪,再决定 |
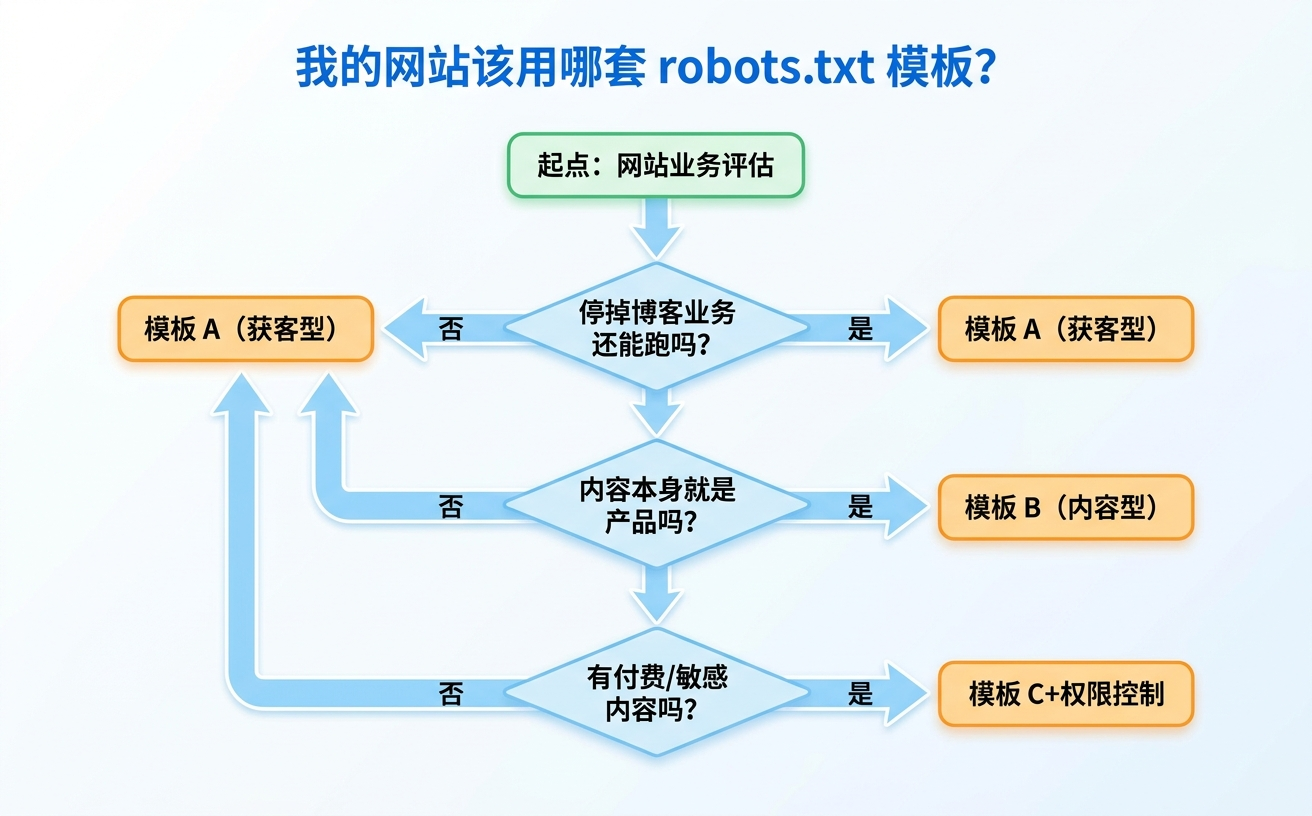
三套 robots.txt 模板选择决策树
用 robots.txt 模板前必看的 4 条提醒
1、文件必须放在根域名下
访问路径是 https://yoursite.com/robots.txt,子目录不算数。规则从上到下读取,越具体的优先级越高。
2、不要再用 Claude-Web 和 anthropic-ai 这两个 user-agent
它们已经在 2024 年废弃。2026 年 Anthropic 的活跃爬虫是 ClaudeBot(训练)、Claude-SearchBot(检索)、Claude-User(用户触发)。很多老 SEO 教程和 CMS 默认配置还在用旧字符串,需要主动检查。
3、规则要和 sitemap 配合
重要页面应出现在 sitemap 中,并确保没有被 robots.txt 误屏蔽。
4、用户触发类 bot 不要作为核心控制对象
ChatGPT-User、Claude-User、Perplexity-User 接近用户主动请求触发的访问,配置重点应放在检索类爬虫和训练类爬虫两类上。
不同平台修改 robots.txt 的方法
平台 | 方法 |
Shopify | 后台无法直接编辑,需要新建 robots.txt.liquid 模板覆盖默认 |
WordPress | 用 Yoast SEO 或 Rank Math 插件编辑,或 FTP 上传静态文件到根目录 |
Webflow | Project Settings → SEO → Robots.txt 直接粘贴 |
Wix | SEO 工具 → Robots.txt 编辑器 |
Ghost | 自托管版本直接修改根目录文件;Ghost(Pro)需联系支持团队 |
Substack | 平台不开放编辑权限,建议把核心内容同步到独立域名 |
Medium | 不支持自定义,平台统一控制 |
自建站 | 直接在 web 服务器根目录放 robots.txt 文件 |
robots.txt 配置完成后怎么验证生效?
第一步:直接打开 robots.txt 文件
在浏览器打开 https://www.example.com/robots.txt,确认看到的是最新版本。如果不是,大概率被 CDN 或 CMS 覆盖了,需要检查 CDN 缓存、CMS 默认规则和服务器路径。
第二步:检查核心页面是否被误屏蔽
页面类型 | 是否应开放 |
首页 | 通常应开放 |
服务页、产品页、行业方案页 | 通常应开放 |
案例页、FAQ、博客 | 通常应开放 |
后台、wp-admin | 应屏蔽 |
购物车、结账页 | 通常应屏蔽 |
内部搜索结果页 | 通常应屏蔽 |
不要让 /blog/、/products/、/services/ 这类高价值目录被误写进 Disallow。
第三步:看服务器日志,过滤 AI bot 访问
日志比感觉可靠。重点过滤这些 user-agent:Googlebot、OAI-SearchBot、GPTBot、PerplexityBot、Claude-SearchBot、ClaudeBot、Google-Extended。观察它们是否访问了核心页面,是否出现 403、429、5xx 等异常状态码。如果 robots.txt 允许但日志显示大量拒绝,要检查 WAF、CDN 和速率限制。
没有服务器日志权限怎么办(比如 Shopify 用户)?
可以用下面这些方式补充判断:
- Cloudflare Analytics 的 Bot 报告功能,能看到分爬虫的流量统计。
- Shopify 用户可以装第三方 Bot Analytics 应用追踪。
- Google Search Console 的“覆盖率报告”看抓取状态。
- 第三方 AI 可见度监测工具。
第四步:用 prompts 测 AI 可见度
技术检查只能证明“能不能访问”,GEO 更关心“有没有被提及”。测试高购买意图 prompts,比如“适合养宠家庭的扫地机器人推荐”、“小型企业适合用哪种 CRM”、“洛杉矶儿童牙科诊所怎么选”、“树叶多的泳池适合哪种泳池清洁机器人”,看 AI 回答中有没有出现品牌、是否正向提及、竞对是否被更多推荐。这一步才真正连接到获客结果。
时间预期:检索类爬虫放行后立即生效,下次 AI 用户提问就能引用到你;训练类爬虫要等下一轮模型训练,通常 3 到 12 个月才反映在模型输出里。
robots.txt 配置的 5 个常见错误
下面这 5 个坑,做技术审计时几乎每个客户都中过至少一个。
错误 1:Cloudflare 在你不知情下托管了 robots.txt
Cloudflare 有个叫 Managed robots.txt 的功能,会自动给常见 AI 爬虫加上 Disallow 规则。约 27% 的 B2B SaaS 和电商站在 CDN 层被默默屏蔽却完全不知道(数据来源:Cloudflare 2025 年 AI 爬虫流量报告)。
自查方法:登录 Cloudflare 后台,进入 Security → Bots,确认“Instruct AI bot traffic with robots.txt”是关闭状态。如果你的 robots.txt 是 Cloudflare 帮你生成的,先关掉这个开关,让源站的文件生效。
错误 2:WAF 规则覆盖了 robots.txt
Cloudflare、Fastly、AWS WAF 都内置了“AI Scraper”或“AI Bot”屏蔽规则集。即使你 robots.txt 写了 Allow,WAF 也会在请求层直接 block,AI 爬虫连 robots.txt 都读不到。
自查方法:在 CDN 后台搜索这些关键词:AI Bot、AI Scraper、Crawler、Bot Protection、Verified Bot,找出现有规则集,确认它和你的策略一致。如果边缘层拦截规则和 robots.txt 不一致,实际结果以拦截规则为准。
错误 3:客户端渲染让 AI 看到一片空白
约 69% 的 AI 爬虫不执行 JavaScript(数据来源:Vercel 和 MERJ 联合工程研究,2024 年)。如果你的网站是 React、Vue、Next.js 的纯客户端渲染(CSR),AI 爬虫看到的就是一个空 div,robots.txt 怎么配都救不回来。
解决方法:上 SSR(服务端渲染)、SSG(静态生成)或预渲染,或确保核心文本内容在初始 HTML 中可见。
错误 4:用废弃的 user-agent 屏蔽 Anthropic
如果你的 robots.txt 里还在写 Claude-Web 或 anthropic-ai,等于没屏蔽。这两个 user-agent 已经废弃,Anthropic 现在用的是 ClaudeBot、Claude-SearchBot、Claude-User。很多老的 SEO 教程、CMS 默认配置、WordPress 插件还在用旧字符串,需要主动检查。
错误 5:把所有 AI 爬虫当成训练爬虫一刀切屏蔽
最常见的策略错误。出于“防止内容被白嫖”的本能,一刀切屏蔽所有带 GPT、Claude 字样的爬虫,结果连给你带流量的 OAI-SearchBot、Claude-SearchBot 也屏蔽了。
后果是品牌从 ChatGPT 搜索答案里完全消失。等几个月后发现 AI 流量为零,回头查才发现是当初一刀切的锅。
正确思路是分层:
目标 | 策略 |
想要 AI 搜索曝光 | 放行检索类爬虫 |
想限制训练用途 | 屏蔽训练类爬虫 |
想保护隐私内容 | 使用权限控制,不是 robots.txt |
想降低噪音抓取 | 屏蔽后台、购物车、搜索页等低价值路径 |
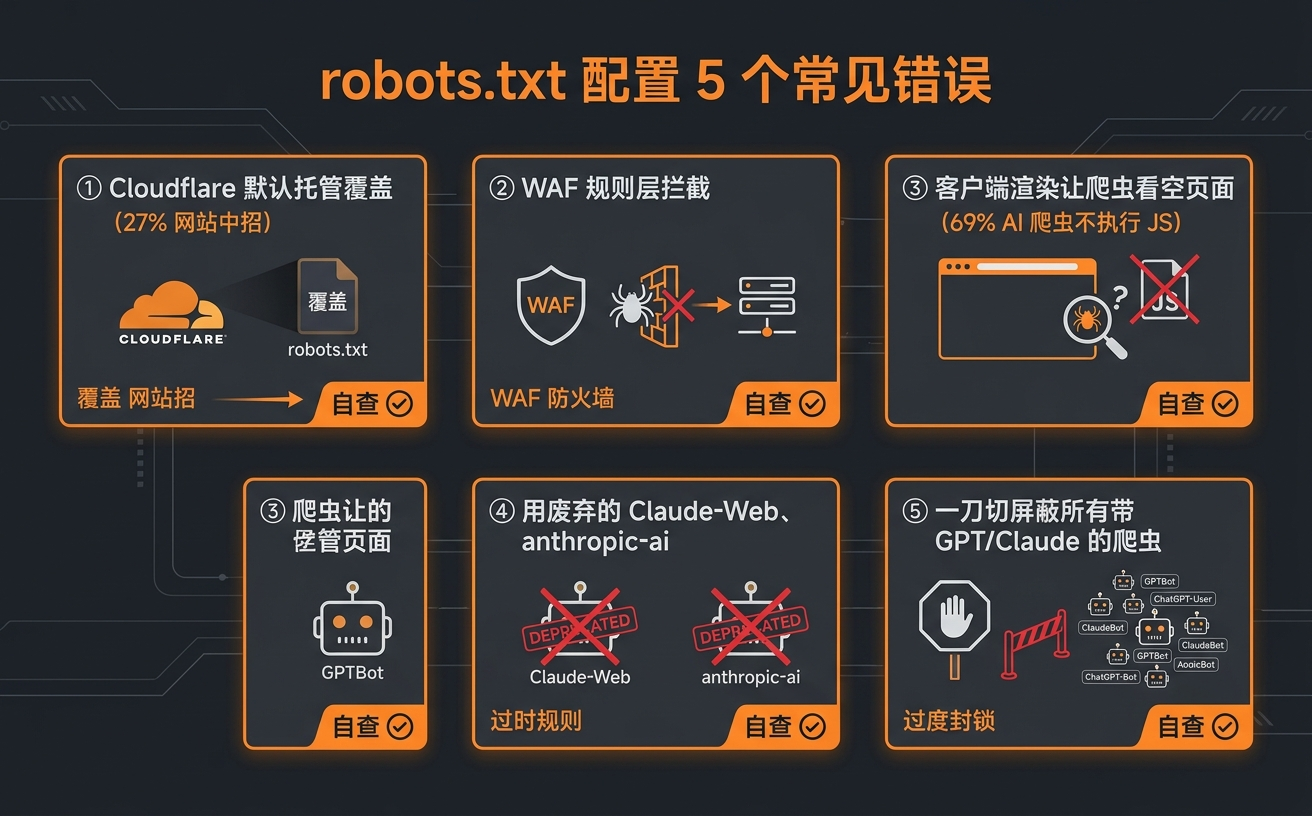
robots.txt 配置 5 个常见错误自查清单
AI 爬虫分几类?训练、检索、用户触发爬虫的区别
很多人看到 GPTBot、OAI-SearchBot、ClaudeBot 会以为它们是一类爬虫,这是 AI 时代 robots.txt 最容易配错的地方。
训练类爬虫
用于收集公开网页内容支持模型训练。
爬虫 | 用途 |
GPTBot | OpenAI 模型训练 |
ClaudeBot | Anthropic 模型训练 |
Google-Extended | Google AI 训练用途控制,不是 Googlebot |
CCBot | Common Crawl,被大量开源 LLM 用作训练集,如 LLaMA 早期、Mistral、各类学术模型 |
Meta-ExternalAgent | Meta AI 和 LLaMA 系列训练;Cloudflare 2025 年统计中流量第二大的 AI 训练爬虫 |
Bytespider | 字节跳动,部分用于 AI 训练,部分用于今日头条、TikTok 内容索引 |
特别注意 Google-Extended:它不是 Googlebot。不要因为想限制 AI 训练,就误伤 Googlebot,影响正常搜索抓取。
检索类爬虫
更接近 AI 搜索和答案引用场景。
爬虫 | 用途 |
OAI-SearchBot | ChatGPT Search 发现和展示 |
PerplexityBot | Perplexity 搜索结果展示和链接 |
Claude-SearchBot | Claude 搜索发现和索引 |
想做 AI 搜索可见度的网站,通常不建议屏蔽检索类爬虫。
用户触发类访问
用户在 AI 工具里粘贴链接、要求总结时触发的访问,更像“用户通过 AI 工具浏览网页”,不是自动爬虫。
名称 | 用途 |
ChatGPT-User | ChatGPT 用户请求触发 |
Claude-User | Claude 用户请求触发 |
Perplexity-User | Perplexity 用户请求触发 |
屏蔽用户触发类访问,意味着用户在 AI 工具里粘贴你的链接要求总结时读不到内容。这种访问通常带高意图,屏蔽往往得不偿失。
常见 AI 爬虫处理建议速查表
爬虫 | 类型 | 处理建议 |
Googlebot | 传统搜索 | 必须放行,AI 时代仍是基础 |
GPTBot | OpenAI 训练 | 看内容是否需要保护版权 |
OAI-SearchBot | ChatGPT 检索 | 想要 AI 答案引用就放行 |
ChatGPT-User | 用户触发 | 建议放行,屏蔽影响用户体验 |
ClaudeBot | Anthropic 训练 | 看内容是否需要保护版权 |
Claude-SearchBot | Claude 检索 | 想要 AI 答案引用就放行 |
Claude-User | 用户触发 | 建议放行 |
Google-Extended | Google AI 训练 | 屏蔽不影响 Google Search 和 AI Overview |
PerplexityBot | Perplexity 检索 | 想要 Perplexity 引用就放行 |
CCBot | Common Crawl | 屏蔽等于切断大批开源模型对你内容的训练访问 |
Meta-ExternalAgent | Meta AI 训练 | 看是否在意 Meta AI / LLaMA 引用 |
Bytespider | 字节跳动 | 取决于是否在意中国市场 |
为什么不能一刀切屏蔽所有 AI 爬虫?
如果把所有 AI bot 都屏蔽,确实能减少内容被抓取的机会。但同时,你也会让网站更难进入 AI 搜索答案、品牌推荐、产品对比和供应商列表。
对企业网站来说,这个代价很高。AI 引荐来的访客转化率比常规自然搜索高约 4.4 倍(指访客进站后最终完成购买或留资的比例,数据来源:Superlines 2025 年 AI 流量分析)。原因是这些访客在进站前已经被 AI 预筛选过意图,离决策更近。
尤其是 B2B 和高客单价行业,用户不会只搜“某某产品多少钱”,还会问“哪种方案适合我”、“哪家公司靠谱”、“某某品牌和竞品有什么区别”。这些问题正在被 AI 搜索重写。
一个常见误解:屏蔽 GPTBot、ClaudeBot、Google-Extended 不会影响 Google 排名。这些爬虫和 Googlebot、Bingbot 是独立系统。屏蔽 Google-Extended 也不影响 Google AI Overview 的可见度。“我屏蔽了 AI 训练会不会掉排名”这个担心可以放下。
另一个要面对的现实:已经被训练过的内容无法通过 robots.txt 撤回。2023 年发布的文章如果已经进入 GPT-4 的训练集,现在屏蔽 GPTBot 只能阻止未来的训练轮次,无法让模型“忘记”已学习的内容。目前 OpenAI、Anthropic、Google 都不接受按内容粒度的撤回请求。所以越早配置 robots.txt 越好,等于在为下一个模型版本止血。
robots.txt 之外还要做什么:llms.txt、ai.txt、sitemap
robots.txt 是地基,2026 年还有几个补充协议和工作要配合做。
llms.txt 是放在根目录的 markdown 文件,主动给 AI 一份“网站知识地图”,告诉它哪些页面最值得读、内容结构是什么。还不是强制标准,但越来越多 AI 引擎在测试性使用。制作成本低,建议做。但它不是 robots.txt 的替代品。
ai.txt 按用途授权,也就是爬来做什么;robots.txt 按身份授权,也就是谁能爬。ai.txt 支持 No-Training、No-Inference、Allow-RAG 等标签,让你能放行 AI 用于搜索引用但禁止训练。版权敏感行业优先做。
TDMRep 是欧盟业务的补充工具。它把许可声明嵌入 HTTP header,根据 EU AI Act 第 53 条,对 GPAI(通用人工智能)提供商具备法律约束力。在欧盟有用户的网站建议了解。
sitemap 仍然重要。它能帮助搜索引擎和部分抓取系统更清楚地发现重要页面。服务页、产品页、行业方案页、FAQ 和博客文章都应该进入 sitemap。
页面内容要能回答真实问题。AI 搜索更常处理完整问题,比如“哪种泳池机器人适合树叶多的泳池?”“小企业选 CRM 应该看哪些功能?”如果页面只写产品卖点不回答这些问题,就算能被抓取也不一定会被引用。
实操优先级是 robots.txt 和 sitemap 必做,核心页面内容能回答真实购买问题必做,llms.txt 建议做,ai.txt 看业务,TDMRep 看是否涉及欧盟。
配好 robots.txt 后,怎么让 AI 真正推荐你的品牌?
AI 能访问页面不代表会推荐你。它还要能理解品牌、业务范围、服务地区、目标客户和核心优势。更重要的是,品牌要出现在高购买意图问题中。
在西品东来的 GEO 服务中,我们不会一上来就只改 robots.txt。我们先选取行业相关、商业意图强、接近购买决策阶段的 prompts,放进自研 GEO 追踪平台测试,重点看两个指标:品牌是否被提及,以及是否为正向提及。
正向提及不是简单出现品牌名,而是指 AI 在合适语境里推荐或认可品牌,比如“适合某类需求”、“可以作为某类方案参考”、“在某个细分场景中有相关经验”。
比如一家家用清洁机器人品牌,我们不会只看“扫地机器人”这种大词,而会测试“适合养宠家庭的扫地机器人”、“可以拖地的机器人吸尘器推荐”、“哪款扫地机器人适合木地板”这些更接近购买决策的问题。
为什么需要自定义追踪 prompts?很多第三方平台只能追踪固定词库,但真实用户不会按固定词库提问。比如牙科诊所的用户可能会问“种植牙疼不疼”、“洛杉矶哪家牙科适合儿童”、“牙齿矫正前要注意什么”——这些问题比“牙科诊所”更接近决策。
西品东来自研的 GEO 追踪平台支持自定义追踪自己的 prompts,也能监控竞对在相关问题中的引荐率变化。你不只是知道品牌有没有曝光,还能看到品牌在哪些问题里被提及、在哪些问题里输给竞对,以及这些提及是否正向。
GEO 追踪平台核心监测指标示例
AI 时代 robots.txt 配置总结
如果网站目标是获客,默认不要屏蔽所有 AI 爬虫。开放搜索和引用类爬虫,按内容类型决定训练类爬虫,保护隐私内容时使用真正的访问控制。
配置前先问三个问题:
- 核心页面是否应该被 AI 看到?
- 原创内容是否需要限制训练用途?
- 隐私内容是否已经用权限保护?
如果已经开放了核心页面,但品牌仍然很少出现在 AI 答案里,问题可能不只在 robots.txt。更常见的原因是页面内容、实体信息和高意图问题覆盖不足。
如果你不确定当前 robots.txt 是在帮你争取 AI 可见度,还是正在悄悄挡住高意图用户入口,可以让西品东来帮你做一次 AI 抓取与 GEO 可见度检查。我们会从 robots.txt、CDN/WAF 拦截、sitemap、核心页面可抓取性、高意图 prompts 提及情况几个层面一起看,找出品牌没有进入 AI 答案的真正原因。
技术配置只是第一步。更重要的是,让 AI 能读懂你、信任你,并在用户接近决策时正确提到你。把这条链路跑通,robots.txt 才不是一份静态文件,而是 GEO 增长系统的入口。
FAQ
AI 时代还需要 robots.txt 吗?
需要。它仍然是管理爬虫访问的基础文件,只是现在要同时考虑传统搜索爬虫和 AI 爬虫。它决定了 AI 是否能读到你的页面,进而影响品牌在 ChatGPT、Claude、Perplexity 答案里的可见度。
屏蔽 GPTBot 会影响 Google 搜索排名吗?
不会。GPTBot 和 Googlebot 是完全独立的系统,OpenAI 和 Google 的爬虫不互通。屏蔽 GPTBot 只是阻止 OpenAI 用你的内容训练模型,对 Google 搜索和 Google AI Overview 都没有影响。这是 2026 年最常见的误解之一。
屏蔽 GPTBot 会影响 ChatGPT Search 吗?
不一定。GPTBot 和 OAI-SearchBot 作用不同,前者是训练爬虫,后者是检索爬虫。如果你关心 ChatGPT Search 可见度,更应关注 OAI-SearchBot 是否能访问,而不是只看 GPTBot。
屏蔽 ClaudeBot 之后 Claude 还会引用我的内容吗?
取决于你有没有同时屏蔽 Claude-SearchBot。ClaudeBot 是训练爬虫,Claude-SearchBot 是检索爬虫,是两个独立的爬虫。如果只屏蔽前者,Claude 仍然会在用户提问时实时取你的页面并引用。
已经被训练过的内容,现在屏蔽 GPTBot 还有用吗?
有用,但只能止血,不能撤回。已经进入模型训练集的内容,目前没有标准化的删除请求机制,OpenAI、Anthropic、Google 都不接受按内容粒度的撤回请求。现在屏蔽 GPTBot 只能阻止未来训练轮次,所以越早配置越好。
Google-Extended 和 Googlebot 是一回事吗?
不是。Googlebot 主要关系到 Google Search 抓取和收录,Google-Extended 更偏向控制部分 Google AI 相关用途。屏蔽 Google-Extended 不影响 Google Search 排名,也不影响 Google AI Overview 的可见度。
想被 AI 推荐应该开放哪些页面?
首页、服务页、产品页、行业方案页、案例页、FAQ、博客文章、关于我们和联系页面。这些页面能帮助 AI 理解品牌定位、服务范围和差异化优势,是 AI 判断“该不该推荐你”的基础。
robots.txt 能保护隐私内容吗?
不能。robots.txt 不是安全工具,它本身是公开文件,且不能强制所有爬虫遵守。隐私内容、会员内容和内部资料应使用登录、权限或服务器访问控制。
Shopify、WordPress 自带的 robots.txt 够用吗?
不够。它们默认配置不区分 AI 爬虫的类型,也不针对 2026 年的 AI 生态做优化。Shopify 用户需要新建 robots.txt.liquid 模板覆盖默认行为;WordPress 用户可以通过 Yoast、Rank Math 插件或直接编辑根目录文件实现。
所有 AI 爬虫都会遵守 robots.txt 吗?
不一定。正规爬虫通常会声明 user-agent 并提供规则说明,但 robots.txt 不是强制安全机制。部分新型 AI 智能体,如 ChatGPT Operator,开始忽略 robots.txt,因为它们的请求被视为“用户主动触发”,需要配合 WAF 一起做防护。
配置 robots.txt 后多久能看到 AI 可见度变化?
检索类爬虫立即生效,下次 AI 用户提问就能引用到你;训练类爬虫要等下一轮模型训练,通常 3 到 12 个月。但是否被 AI 提及还取决于页面内容、实体信息、外部信号和用户问题匹配度。
没有 robots.txt 文件会怎样?
通常表示默认允许抓取。但如果网站使用 CDN、CMS 或安全插件,最终访问到的 robots.txt 可能由系统自动生成。应直接打开 /robots.txt 检查实际结果。
robots.txt 配好了,为什么 AI 还是不提我的品牌?
常见原因有三个:页面内容没有覆盖高购买意图问题、品牌实体信息不清晰、外部信号不足。此时应结合 prompts 追踪结果继续优化,从技术抓取、内容结构和外部信号三个维度找原因。
llms.txt 必须做吗?
不必须。它是值得关注的补充方案,但不是 robots.txt 的替代品。建议先把 robots.txt、sitemap、核心页面内容和技术抓取问题处理好,再考虑 llms.txt。