判断一份 GEO 成功案例是否靠谱,不能只看它讲得多漂亮,更不能只看一张 AI 回答截图。真正有参考价值的案例,必须能被验证、能被复盘,也能说清楚结果从哪里来。
很多企业在采购 GEO 服务时,容易被“品牌被 AI 推荐了”“AI 引用率提升了”“案例效果很好”这类说法吸引。但这些话本身并不能证明项目成功。因为 AI 答案会波动,测试环境会影响结果,数据口径也可能被包装。一个案例如果没有时间、平台、样本、基线和归因,它就很难成为可靠的决策依据。
这篇文章不再给你堆更多成功案例,而是给你一套判断框架。你可以用它快速判断服务商给出的 GEO 案例,是有参考价值,还是只适合放在 PPT 里。
一、靠谱的 GEO 成功案例必须有完整证据链
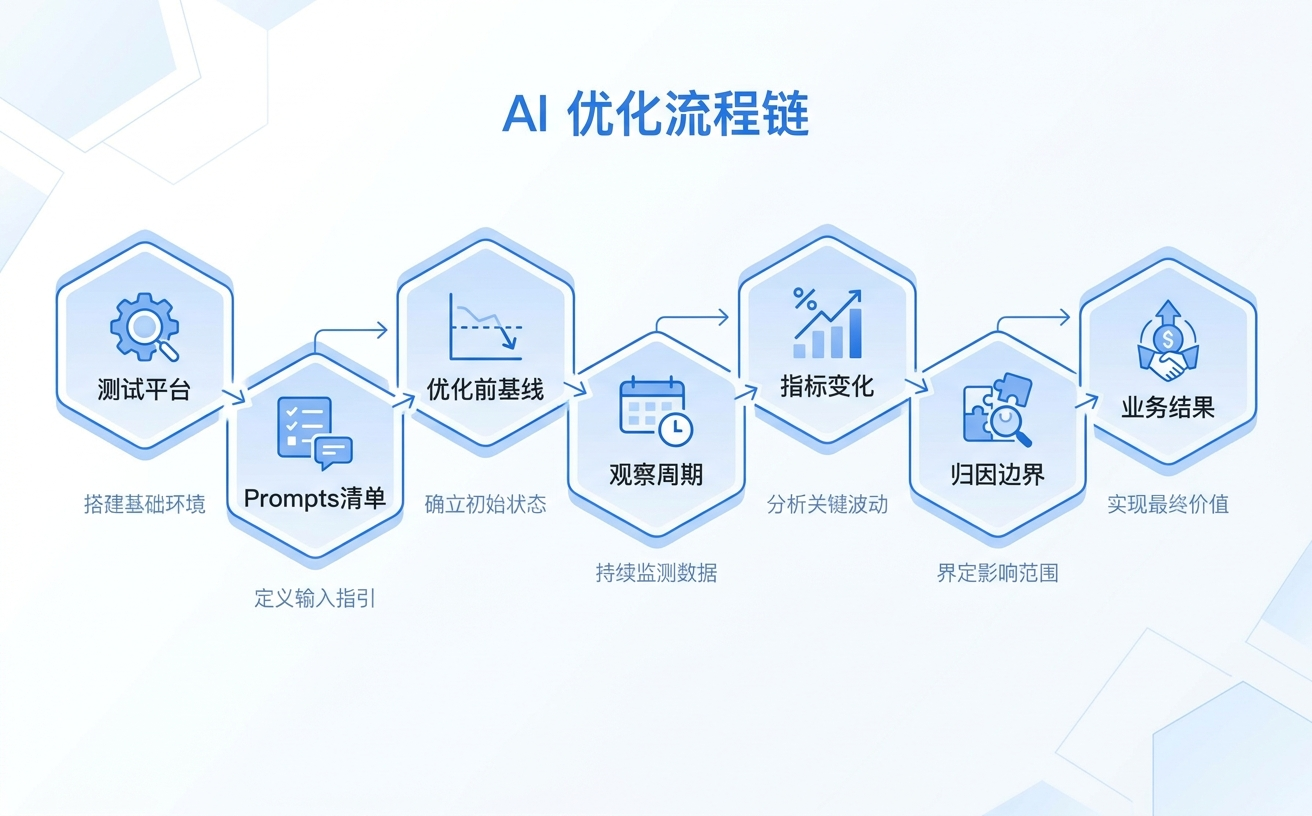
GEO成功案例证据链7要素结构图
一个能信的 GEO 成功案例,至少要说清楚七件事:
- 在哪个 AI 平台测试:ChatGPT、Perplexity、豆包、Google AI Overviews,机制完全不同。
- 测试了哪些 Prompts:用户真实会问的问题,而不是为了好看挑出来的。
- 优化前的基线状态:品牌被提到多少次、官网有没有被引用、竞品出现率多少。
- 持续观察了多久:单次截图无意义,至少要 4–8 周趋势。
- 哪些指标变了:品牌提及率、正向提及率、引用率、AI referral。
- 变化能不能合理归因:增长是 GEO 带来的,还是同期的品牌投放或 PR?
- 最后有没有带来真实业务结果:访问、咨询、Demo、CRM 线索。
Prompts,就是用户向 AI 提出的问题。GEO 不能只测一个问题,真正有价值的测试要覆盖用户决策链——从“怎么选”(信息型),到“A 和 B 哪个好”(比较型),到“小户型适合哪个品牌”(决策型)。
AI referral,就是 AI 平台带来的网站访问。比如用户从 ChatGPT 点击进入官网。这个指标能判断 AI 可见度是否真的转化成了流量。
归因边界,就是哪些增长可以合理算作 GEO 影响,哪些不能。不区分这点,就可能把 SEO 自然增长、品牌投放效果、PR 带来的流量,全部包装成 GEO 成果。
GEO 优化前基线报告长什么样?
“基线”这个词听起来很专业,但很多服务商讲不清。一份合格的基线大概是这样:
基线维度 | 合格标准 |
样本量 | 50–100 个 Prompts,不是 10 个,也不是 1000 个 |
平台数 | 至少覆盖 3 个主流 AI 平台,如 ChatGPT、Perplexity、豆包或 Gemini |
测试周期 | 连续 2 周,每个 Prompt 每天至少测 1 次 |
总样本 | 50 个 Prompts × 3 个平台 × 14 天 ≈ 2100 次测试 |
基础数据 | 品牌提及次数、提及率、引用源、竞品出现率、答案位置 |
举个例子。某净水器品牌的基线报告显示:在 60 个相关 Prompts、3 个平台、连续 14 天的测试中,品牌被提及 17 次,提及率 0.67%;其中正向提及 9 次,引用品牌官网 1 次,主要竞品出现 143 次。有这个底子,才能谈优化后的对比。
如果服务商只甩一句“优化前你们基本没出现过”,这不是基线,是说辞。
西品东来在做 GEO 服务时,会先选取行业相关的、高商业意图和高购买转化阶段的 Prompts。比如客户做户外露营装备,我们盯的是“家庭露营帐篷推荐”“4 人帐篷选哪个牌子”,而不是“什么是露营”。这些 Prompts 更接近真实购买场景,GEO 效果才能直接反映在业务上。
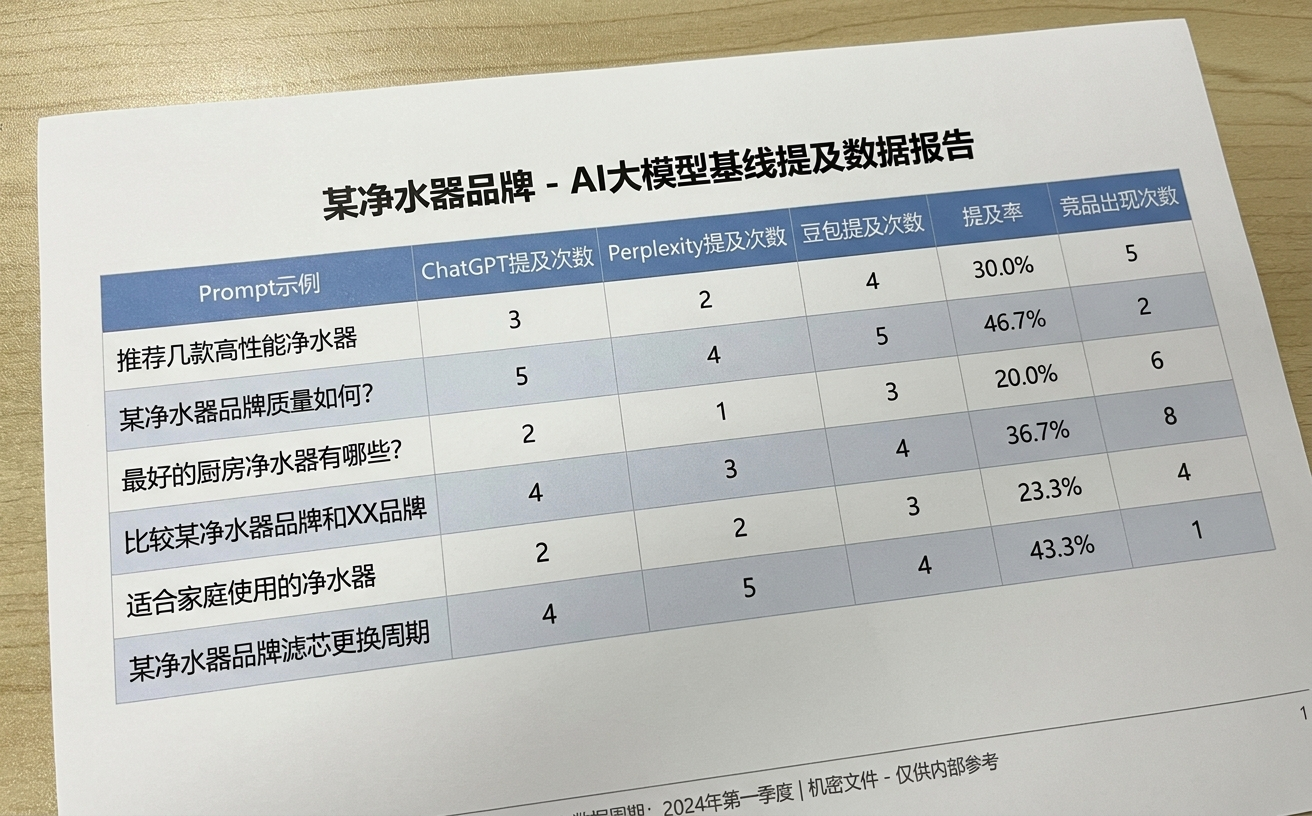
GEO优化前基线报告数据样本
二、GEO 成功案例要看的 7 个核心指标
真正能判断 GEO 效果的指标,分成三层。
第一层:AI 是否知道你
品牌提及率:品牌在目标 Prompts 中被 AI 提到的比例。比如 100 个问题里,优化前出现 5 次,优化后出现 22 次。
品牌描述是否准确:AI 对品牌的描述对不对,有没有错误信息混进去。
AI 连品牌是什么都说不清,后面的推荐和引用都难以稳定。
第二层:AI 是否愿意推荐你
正向提及率:AI 是用积极推荐的方式描述你,还是中性提到,甚至负面提醒?比如“避免选择这类品牌”。同样是出现,正向和负向价值完全相反。
引用率:AI 回答是否引用官网、博客、产品页或行业内容作为来源。被引用比被提到更有价值,说明你的内容资产正在成为 AI 的信息来源。
答案位置:品牌在答案开头出现,还是列表末尾?是被重点推荐,还是顺带提到?
正向提及率怎么判断?
看 AI 回答里描述品牌时用的形容词和动词:
提及类型 | 常见表达 |
正向 | “推荐”“适合”“口碑好”“性价比高”“值得考虑” |
中性 | “也有”“另一个选择”“市场上还包括” |
负向 | “避免”“不建议”“有用户反馈问题”“需谨慎” |
判断方式可以人工标注,适合样本量小;也可以用 AI 辅助标注,适合大样本。关键是要有判断规则,不能让服务商自己说“我们都是正向提及”。
第三层:用户是否因此行动
AI referral:AI 平台带来的网站访问。
线索和转化:对 B2B 企业来说,表单提交、Demo 预约、CRM 销售线索才是终点。
竞品出现率变化:同一组 Prompts 里,你和竞品的此消彼长。
只能展示第一层数据的案例,只是认知层案例。能走到第三层的,才是真正的商业案例。
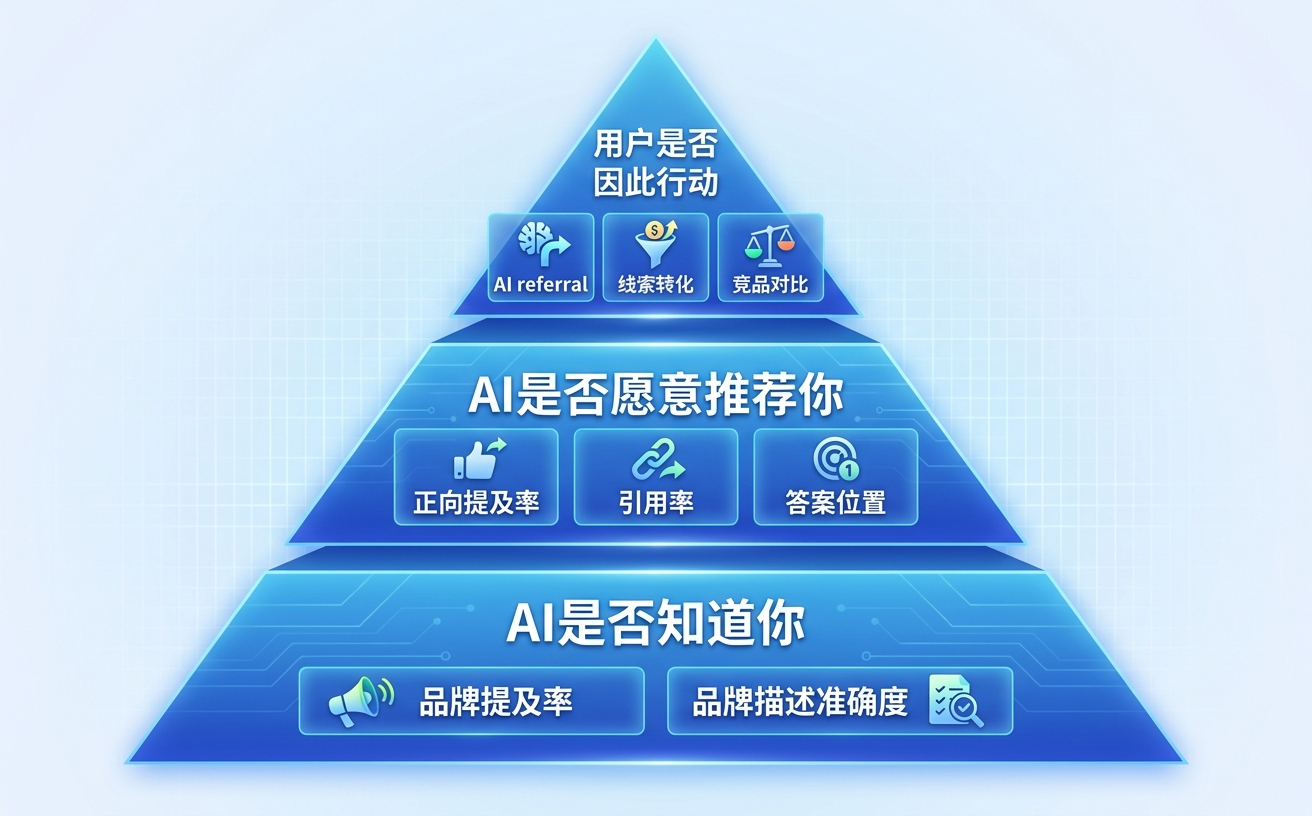
GEO效果评估三层结果金字塔
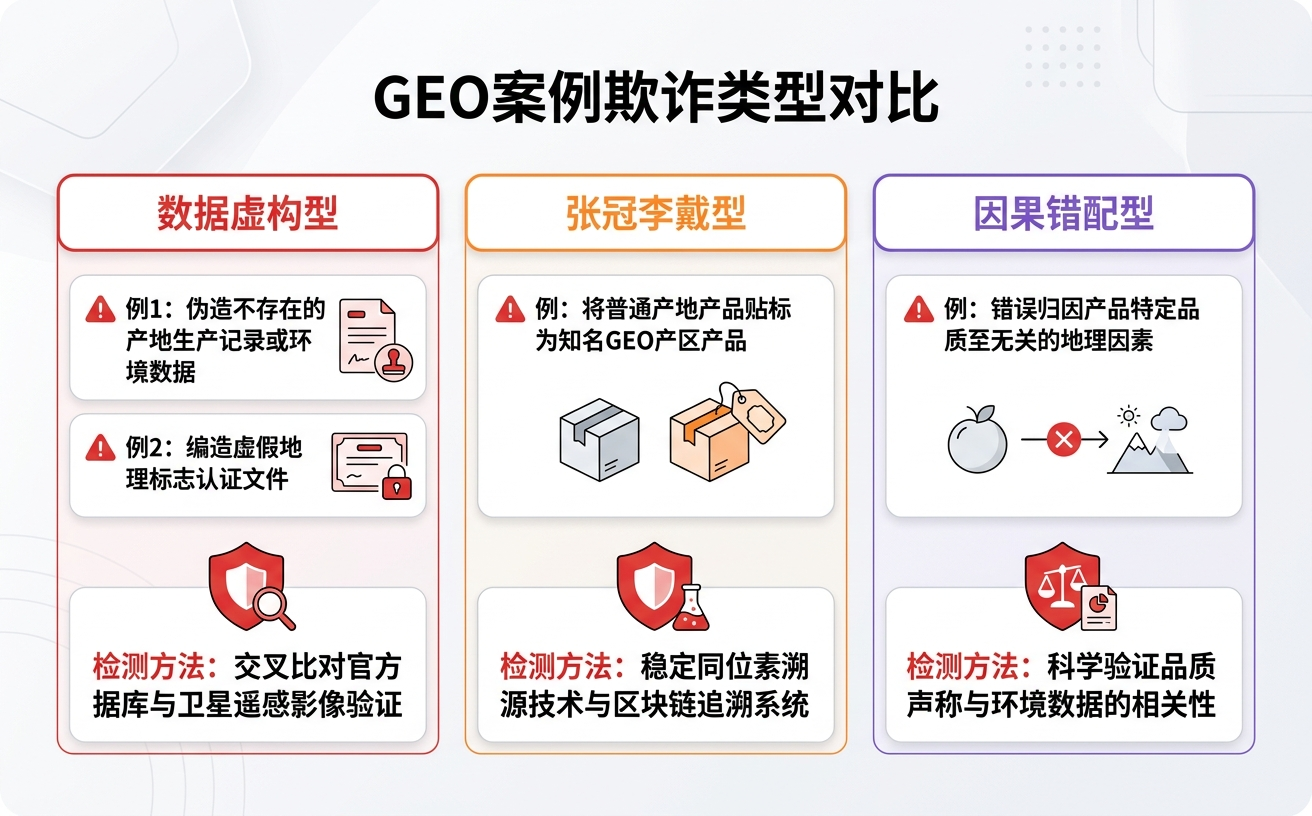
三、3 类常见的 GEO 案例造假手法
第一类:数据虚构型
最常见的是编百分比。“AI 引用率提升 300%”“品牌提及率增长 500%”。
百分比越大、基数越模糊,水分越大。提升 300% 听起来很猛,但如果基数是从 1 次涨到 4 次呢?也是 300%。每次看到百分比,都要问清楚基数。
更隐蔽的变形是“挑成功样本”——可能测试了 100 个问题,只展示成功的 3 个,剩下 97 个失败样本你看不到。
第二类:张冠李戴型
把公开报道里某个品牌的 GEO 成果,包装成自己服务过的客户。
识别方法是把案例里的品牌名扔进 Google 搜一下,看有没有第三方媒体报道,报道里提到的服务商是不是说话的这家。
第三类:因果错配型
最隐蔽。客户流量确实涨了,数据是真的,但涨的原因不是 GEO——可能是同期上了一波品牌投放、做了 KOL 合作,或者赶上行业风口。服务商把功劳全揽到自己头上。
识别方法是要求拆分流量来源,单独看 AI referral 的贡献,而不是看总流量。
GEO 案例造假之所以普遍,根本原因是行业还没有像 Google Search Console 那样的官方权威工具。AI 回答本身又是黑箱,给了服务商“算法变了所以查不到”的万能借口,而买方对生成式 AI 原理普遍不熟,容易被 RAG、向量召回这些术语带走节奏。
GEO案例三类造假手法识别图
四、3 分钟亲手验证 GEO 成功案例的方法
不需要付费工具,3 步就能跑完。
第一步:在 AI 平台亲自验证关键词
把案例里的关键词复制到 ChatGPT、Perplexity 或豆包,直接搜。看三件事:这个品牌出现了吗?在第几位?引用源是哪个网站?
如果只引用品牌自家官网,含金量很低——AI 本来就倾向引用官网。真正有价值的引用,来自第三方测评、专业媒体、问答社区。
但 AI 每次回答都不一样,怎么办?
可以用“小样本 + 多次测试”做粗略验证:
- 选 3–5 个核心 Prompts。
- 每个 Prompt 用 2–3 种不同问法表达,比如“敏感肌洁面推荐”“敏感肌用什么洗面奶”“敏感肌洁面哪个牌子好”。
- 每种问法测 3 次。
- 这样每个 Prompt 有 6–9 次测试样本。
判断标准:品牌在 6–9 次测试里出现 3 次以上,可以认为案例有真实基础;低于 2 次,大概率是包装。
这种验证不严谨,但作为采购前的初筛已经够用。要更准确的数据,需要专业监测工具。
第二步:核查数据的可追溯性
让服务商提供带时间戳和 URL 的原始后台截图,不能只给 PPT 图表。问清楚监测工具——市面上的 AthenaHQ、Profound、Otterly 等第三方平台数据相对中立。如果服务商说“用我们内部自研系统”,追问能不能让你登录看实时数据。只能看月报的,基本是黑箱。
靠谱的服务商,通常用“第三方平台 + 自研平台”双轨监测:
监测方式 | 作用 | 局限 |
第三方平台 | 负责行业普查,固定词库、固定模板,数据中立,可以横向对比行业内品牌的整体可见度 | 不能定制,贴不到具体业务 |
自研平台 | 负责业务深度,可以自定义企业自己的 Prompts,按业务场景分组,追踪竞对在相关 Prompts 中的引荐率变化 | 自研数据如果不交叉验证,可能有偏差 |
两套数据交叉验证,既保证中立性,又贴近业务场景。只用其中一种,都有盲区。
西品东来自研的 GEO 追踪平台,就是为了解决第三方平台“无法定制”的痛点。每个行业的客户问法都不同,家用电器、宠物食品、工业设备、SaaS 软件,用户的问题链完全不一样。我们的平台支持企业自定义追踪自己的 Prompts,按业务场景分组,包括认知阶段、比较阶段、决策阶段,并同步监控竞对的引荐率变化,也就是 AI 在相关问题中推荐或提到某个品牌的比例。
即使用了自研平台,我们仍然建议客户配合第三方工具做交叉验证。
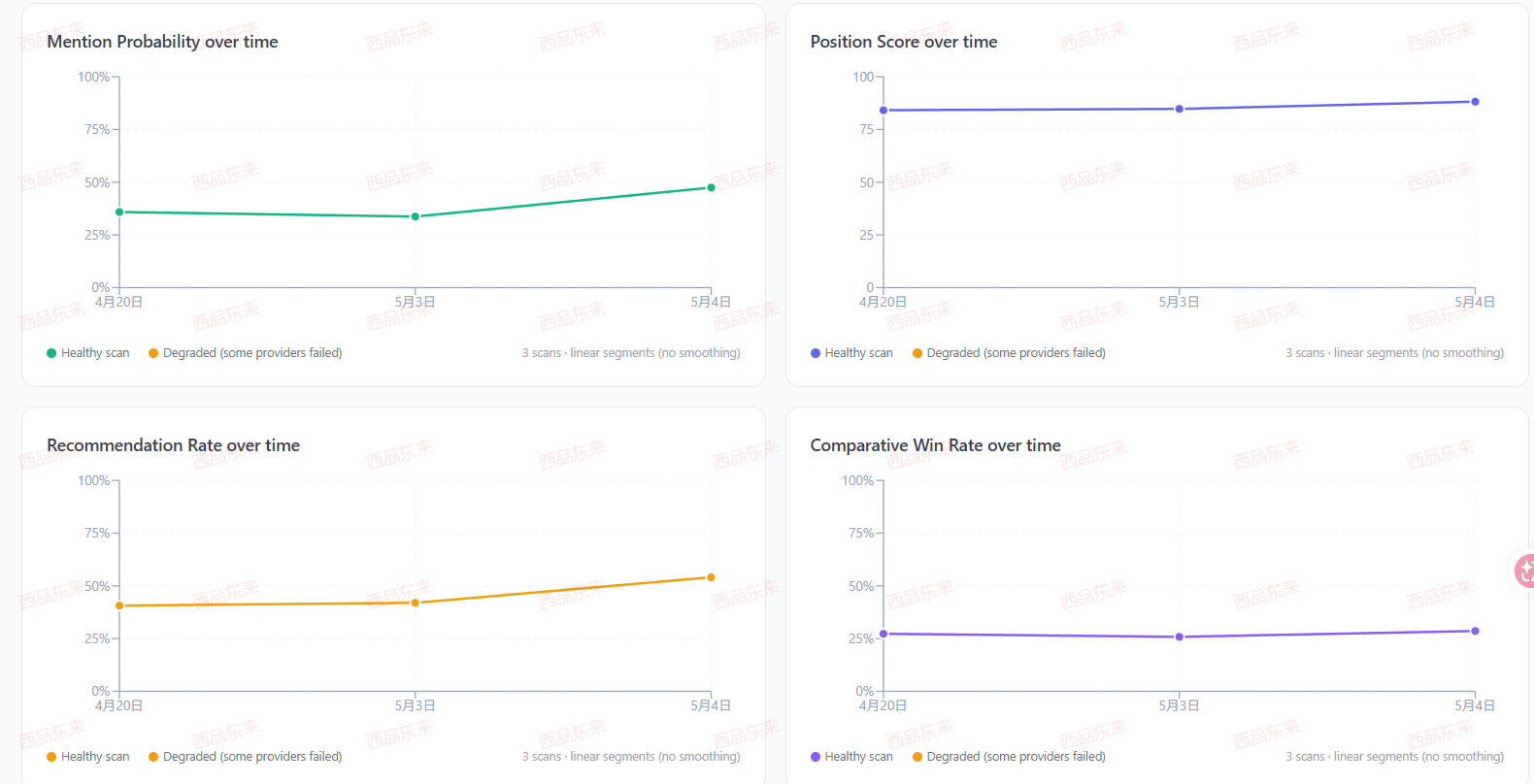
西品东来自研GEO追踪平台数据后台
第三步:交叉验证流量
用 SimilarWeb 或 Ahrefs 的免费版,查这个客户的官网流量曲线,看时间是否对得上。案例说“Q4 开始优化,3 个月后流量翻倍”,那就看 Q4 到次年 Q1 的数据是不是真翻了。
更细一层,看流量来源里 AI referral 的占比有没有显著变化——整体流量涨了但 AI 带来的没涨,说明涨的部分跟 GEO 无关。
五、评估 GEO 服务商必问的 6 个问题
带着这张清单去谈判。服务商答得上来,案例就靠谱一半;答不上来,你心里有数。
你要问的问题 | 靠谱的回答长什么样 | 危险信号 |
这个客户是什么行业、什么规模? | 户外用品,年营收 8000 万 | “不方便透露” |
Prompts 是怎么选的? | 来自用户决策链,覆盖比较型和决策型 | 只挑容易出现品牌的问题 |
优化前的基线数据是什么? | 给出具体提及率和竞品对比 | “之前基本没出现过” |
用什么工具监测引用率? | 第三方平台 + 自研平台双轨 | “我们内部自研的,不外露” |
这个客户现在还在续约吗? | 已续约 2 年 | 含糊带过 |
同样方法在我的行业能复现吗? | 给出能做和做不到的边界 | “100% 没问题” |
最后一个问题最关键。说“百分百能复现”的服务商,都不能信。GEO 效果跟行业竞争度、品牌基础、内容资产积累深度都有关,没有 100%。
六、GEO 案例能证明什么,不能证明什么
GEO 案例能证明优化方向是否有效。一组 Prompts 连续数周出现正向变化,品牌提及增加,官网内容被引用,竞品差距缩小,这说明方法论本身可参考。
GEO 案例能证明品牌可见度是否提升。在行业问题、产品对比、供应商推荐类 Prompts 里,品牌出现频率提高,意味着品牌开始进入 AI 的答案范围。
但它不能证明每次都会被推荐。AI 答案不是固定页面,会随时间、地区、上下文变化。任何案例都不能保证未来每一次搜索都出现同样结果。
它也不能单独证明销售增长。销售增长还受产品、价格、网站转化率、销售能力、市场需求影响。GEO 可以影响用户认知和调研路径,但不能独自承担全部结果。
承诺“保证被 AI 推荐”“保证带来多少线索”的服务商,要么不专业,要么不诚实。
七、常见问题 FAQ
Q1:GEO 成功案例只看 AI 截图靠谱吗?
不靠谱。截图只能说明某一次出现过,不能证明长期稳定,也不能证明带来访问、线索或转化。
Q2:GEO 效果一般多久能看到?
通常 2–3 个月可看到引用率变化,6 个月以上才能看到转化影响。承诺“两周见效”的,基本是低质内容刷量,长期会反噬。
Q3:B2B 和 B2C 的 GEO 案例验证方式有什么区别?
B2B 要看决策链上多个角色的搜索路径,B2C 看消费场景 Prompts 即可。
B2C 的 Prompts 集中在购买前的最后一公里——“哪个好”“怎么选”“适合 XX 的品牌”。验证看提及率和短周期内的转化即可。
B2B 要分层测试:技术评估层,如“CRM 系统对比”“企业级 SaaS 架构”;采购决策层,如“XX 行业供应商推荐”“企业级方案定价模式”;风险评估层,如“XX 供应商靠谱吗”“替代方案有哪些”。每一层对应的决策角色不同,包括技术、采购、CXO,GEO 要在多层都建立可见度。
B2B 转化也不能只看短周期。从 AI 看到品牌,到走到询盘签约,可能要 3–6 个月。归因要看整个决策周期里 AI 的贡献,而不是只看“这条线索是不是 AI 直接带来的”。
Q4:没有 SEO 基础的企业能做 GEO 吗?
可以做诊断,但不建议直接大规模做 GEO。因为 GEO 需要内容、技术、品牌信息和外部信号作为基础。没有 SEO 基础时,通常要先补官网内容和可抓取性问题。
Q5:服务商说“签了 NDA 不能透露”,可信吗?
NDA 保的是客户名,不保数据维度。靠谱的服务商会用“某 Top3 电商品牌”“年 GMV 10 亿级护肤品牌”这种方式描述,而不是含糊的“某知名品牌”。
Q6:小预算企业怎么低成本验证服务商?
最便宜的办法是要求做一次 1–2 周的小范围试点。锁定 3–5 个关键 Prompts,看服务商能不能在试点期内带来可观测的引用率变化。试点结果好,再签长约。
写在最后
真正靠谱的 GEO 成功案例,会说清楚平台、Prompts、基线、周期、指标、归因边界。只展示一张漂亮 AI 截图就让你签合同的,是包装,不是案例。
对出海企业来说,GEO 的价值不在于追逐某一次 AI 推荐截图,而在于建立一套可监测、可复盘、可持续优化的增长系统。
如果你正在评估 GEO 服务,或者想知道自己的品牌现在在 ChatGPT、Perplexity、Google AI Overviews、豆包等 AI 平台里的真实表现,可以先从一次 GEO 可见性诊断开始。西品东来会帮你梳理高商业意图 Prompts、建立优化前基线、对比主要竞品的 AI 引荐率,并判断哪些内容和信源最值得优先优化。
先看清楚现状,再决定要不要投入;先验证方向,再谈长期增长。这才是更稳的 GEO 合作方式。