快速导航文章目录+

GEO 竞争分析分两步:先用 prompt 测试找出 AI 实际引用的对手(包括同行、内容站点、规范信源三类),再分三层拆解(可见性诊断、内容拆解、信任根基),找到差距,再进行针对性优化提升。
不建议直接拿 SEO 那份竞品名单来用,SEO 时代抢的是 Google 排名,对手就是和你一起排在前几页的同行。但GEO 不一样。AI 给用户答案时,可能引用 Reddit 一个帖子、Wikipedia 一个词条、行业媒体一篇旧文,甚至直接给一段”中立总结”不点名任何公司。
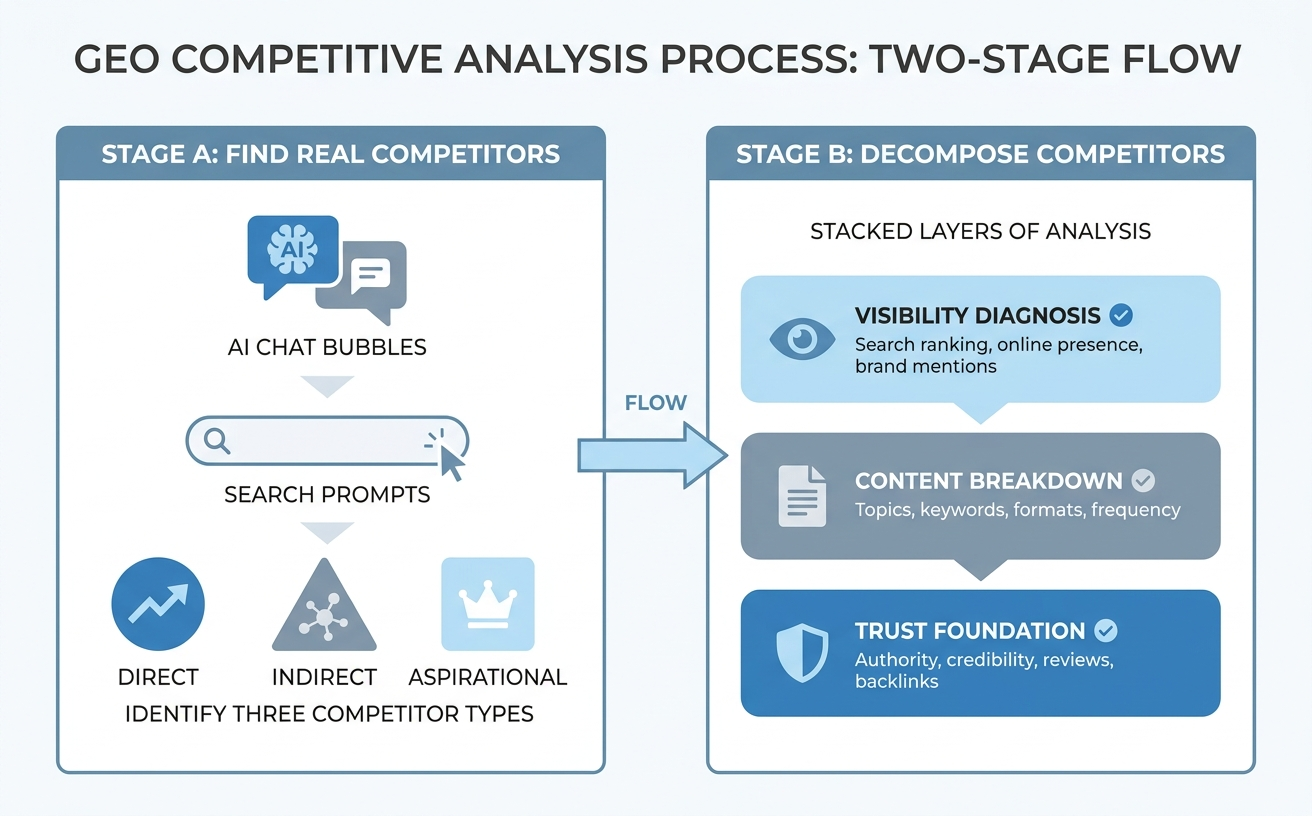
GEO 竞争分析的两阶段框架:先找对手,再拆对手
如何用 GEO 找出真正的竞争对手
第一步:列 10–30 个 prompt
不要从关键词出发,要从客户怎么问 AI 出发。用客户口吻写,不要用行业术语。
按这五类各出几条:
- 品类词:”最好的 XX””XX 怎么选”
- 对比词:”A 和 B 哪个好””XX 替代方案”
- 成本词:”XX 多少钱””XX 价格受什么影响”
- 选择词:”如何挑选 XX 供应商””XX 选购避坑”
- 推荐词:”推荐几个 XX””XX 哪家做得好”
举个例子,如果业务是钢结构出口,按这五类写出来大致是这样:
- Best steel structure manufacturers in China for export(品类)
- Prefab steel structure vs concrete for warehouse(对比)
- How much does a steel structure warehouse cost per square meter(成本)
- How to choose a steel structure supplier for overseas project(选择)
- Recommend steel structure companies for a 10000 sqm factory in Vietnam(推荐)
把这 10–30 个问题整理成一张表,形成你的 prompt 集——后面所有分析的输入。
几个落地细节:
海外业务一定要用英文 prompt。 客户在 ChatGPT、Perplexity 上主要用英文。中文 prompt 跑出来的是国内视角,两套答案差很多——同一个问题用中文和英文问 ChatGPT,引用的信源经常完全不重合。
先求质再求量。 第一次跑 10 个就够,但这 10 个要覆盖完整决策链:客户从”我有这个需求”到”我要下单”会经过的所有问题节点。漏掉成本类或选择类,决策类问题的数据你就拿不到。
对比类 prompt 里要带具体对手名。 “Prefab steel vs concrete” 是泛对比,AI 给的是教科书答案。”Company A vs Company B” 才能逼出 AI 的真实立场——也能直接看到 AI 怎么描述你的竞品。
一时想不出 30 个 prompt? 用 AlsoAsked、AnswerThePublic 这类工具拉真实搜索问题做种子。它们抓的是 Google 真实搜索数据,比凭空想准得多。
第二步:跑测,记录
至少跑这三个:ChatGPT、Perplexity、Google AI Overview。海外 B2B 业务再加 Google AI Mode 和 Bing Copilot——B2B 用户在 Bing 上的活跃度被严重低估,特别是欧美企业用户。国内业务加 DeepSeek、Kimi、豆包。
每个 prompt 在每个平台问一次,用一张表记下来(Excel、飞书表格、Notion 都行)。表结构建议这样:
| Prompt | 平台 | 提到的品牌 | 内容型信源 | 引用 URL | 是否提到我 | 提到时的语境 |
第一次很多人用一张表装所有数据,跑到第三个平台行数就爆炸。建议每个平台一个 sheet + 一个汇总 sheet,汇总只留品牌名和出现次数。后面算 SoV、挑 Top 名单都从汇总表拉。
最后一列”语境”别漏。AI 提到你不一定是好事——”XX 服务一般”和”XX 性价比突出”频率一样性质相反。只统计”是否被提到”会把负向曝光当成可见度,方向就错了。语境列建议三档标记:+(正向)/ 0(中性)/ −(负向)。
还有同一个 prompt 不同时间问 AI 答案会变——背后有版本更新、检索源轮转、缓存策略多种因素。重要 prompt 这样跑:同一天上午跑一遍,隔 2–3 天再跑一遍,对比两次结果。 一致出现的对手是稳定信号;只在某一次出现的标注”待观察”,别当结论。
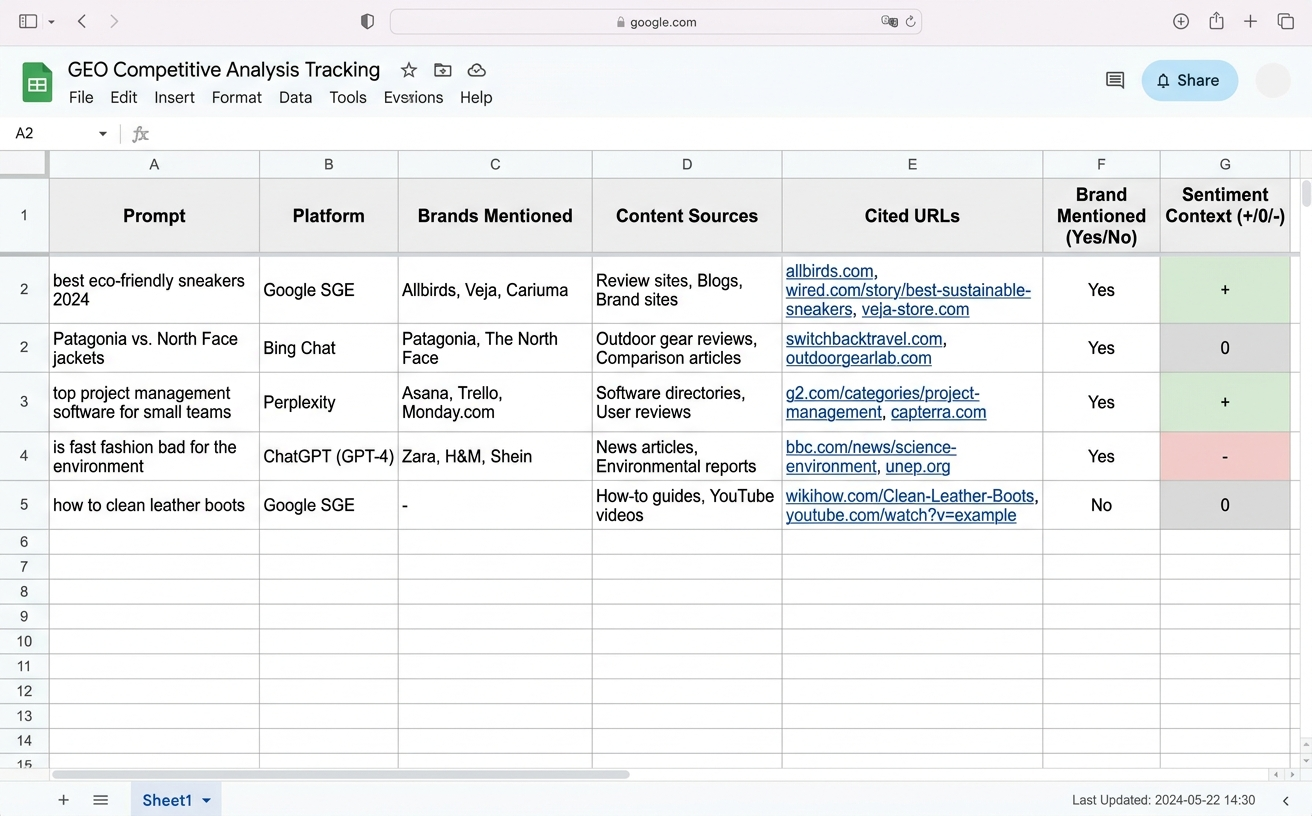
prompt 测试记录表样板:每一列都有用
第二步进阶:从手动转半自动可以用什么工具
以下工具是给已经跑过 1–2 轮、想升级监测频率的团队看的。如果你还没跑过一轮,跳过这节直接到第三步——工具买太早会让你被仪表盘绕晕。
prompt 上了 50 个、平台超过 3 个、要每周跑一次时,手动开始崩。这时候可以考虑工具。
最常见的两个入口:
- OtterlyAI——目前最便宜的成熟方案,$29 起跑 10 个 prompt。多份 2026 评测里在性价比维度评分最高。适合从手动转半自动的过渡期。
- Profound——G2 Winter 2026 AEO Leader,覆盖 10+ AI 引擎,规模化监测能力最强,$99/月起。适合中大型品牌。
其他几个值得知道的:
- AthenaHQ:强项是 Action Center,直接给”接下来该写什么、改哪个页面”的建议,比 Profound 更偏执行。
- Scrunch AI:独特功能 Replacement Analysis——你从 AI 答案里掉出去时,它告诉你是谁取代了你。SaaS 这种竞争激烈的品类很有用。
- Semrush AI Visibility Toolkit / Ahrefs Brand Radar:团队已经在用 Semrush 或 Ahrefs,直接开通 AI 模块。Semrush 支持不用先输入 prompt 就能做竞对域名分析——输一个对手域名,它告诉你这个对手在哪些 AI prompt 下被引用。
选工具的核心标准是能不能直接驱动行动,不是覆盖了多少 AI 引擎——市面上多数工具是漂亮的监测仪表盘。详细对比是另一篇话题,这里只给入门级建议。
第三步:把对手分成三类
跑完之后你会看到三类:
直接同行——你卖钢结构,跑出来的其他钢构公司。预期之内。但数量经常比想象中少,因为 AI 在很多问题下不点名公司,只给方法论。
内容型对手——行业垂直媒体、Reddit、Quora、知乎、LinkedIn 长文、Alibaba 和 Made-in-China 的指南页。它们没在卖你的产品,但 AI 把它们当中立权威,引用频率极高。
基础设施型信源——Wikipedia、AISC 这种行业规范文档、协会报告、政府统计、学术论文。AI 几乎逢问必引。
大多数人只盯第一类,漏掉后两类等于自动放弃——因为后两类才是 AI 引用得最多的。
一个反常识的观察:内容型对手里,B2B 平台的”指南页”被引频率经常超过想象。比如 Alibaba 的 buyer guides、Thomasnet 的行业知识库、Globalsources 的产品介绍页——这些页面没几个人当成”内容资产”看,但 AI 极度信任它们,因为结构化好、覆盖度全、更新频繁。如果你的品类有大型 B2B 平台,把它们的指南页当成头号内容型对手研究。
第四步:从这堆里挑 Top 5–10 重点拆
不是按出现次数排,要加权:
- 被引用 > 仅被提到。 被 AI 在答案正文里提到名字是基础,被它把链接列在”来源”区是更强信号。
- 出现在前 3 位 > 出现在后面。 AI Overview 和 Perplexity 的引用是有顺序的,第一个引用源比第十个权重高得多。
- 出现在推荐 / 选择 / 对比这类决策类问题 > 出现在科普类问题。 决策类问题离转化最近,对手在这里赢比在科普类问题赢值钱得多。
- 多平台一致出现 > 只在一个平台出现。 多平台说明对手的内容已经穿透到多个 AI 模型的检索池;单平台可能只是单次缓存或某个模型的偏好。
按这个原则筛出来的 Top 5–10,才是值得花 2–3 天深拆的对象。
A 阶段做完,你应该手上有三样东西:分好类的真实对手名单、每个对手在哪些 prompt 下出现、AI 反复引用的中立信源清单。
如何拆解对手在 GEO 上做对了什么
按下面这个三层结构拆。这三层有内在递进关系:
- 第一层:可见性诊断——这个对手到底有多强?
- 第二层:内容拆解——对手的内容是怎么赢的?
- 第三层:信任根基——对手为什么 AI 信它?
第一层决定要不要花资源拆它;第二层是对手的”招式”,可以学;第三层是对手的”根基”,决定你能追多近。这三层对应三种不同优先级的优化动作——第二层最容易补,第三层最难补。
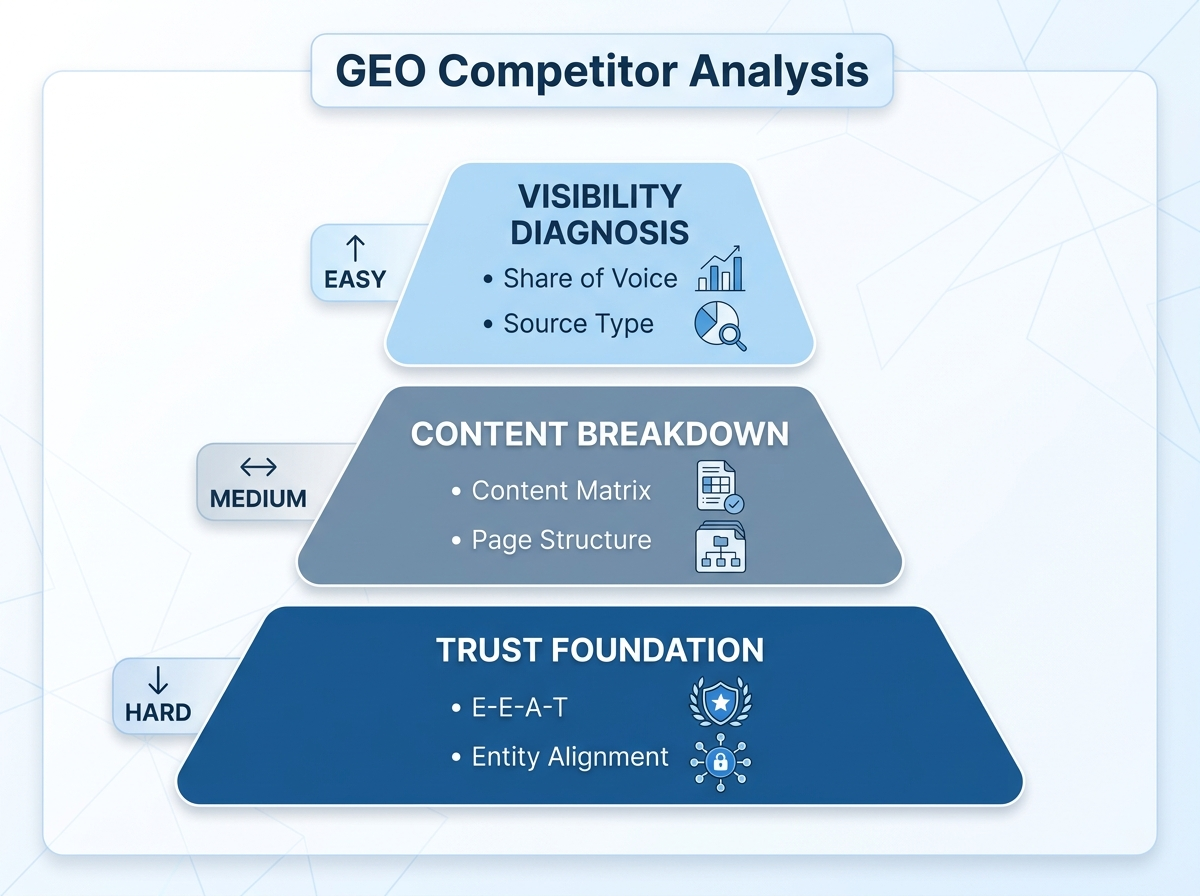
从可见性到信任根基的三层结构递进拆解
第一层:可见性诊断(这对手到底有多强)
1. 算 Share of Voice。
SoV 没有统一标准算法,相对常用的一种是:这个对手在所有 prompt 中被引用的次数 ÷ 所有品牌被引用的总次数。不是除以 prompt 总数——前者反映品类内的相对密度,后者反映绝对覆盖率,两个数能差很多。挑一个固定下来,关键是前后一致,不是哪个算法”对”。
算 SoV 时把”内容型对手”和”基础设施型信源”单独算,不要和品牌混算。混算会出现 Wikipedia 占 30%、所有品牌加起来才 40% 的画面,看上去吓人但没有可比性——你不是要打败 Wikipedia,是要在剩下的品牌池里看你和同行的相对位置。
同一对手在不同 AI 模型里 SoV 可能差异很大——这不是数据错误,是不同模型的检索后端不同(AI Overview 基于 Google 索引、ChatGPT 基于 Bing、Perplexity 自建索引、Gemini 深度依赖 Google Knowledge Graph)。建议按模型分别算 SoV,再合成总览,不要直接平均。
2. 看信源类型分布。
把对手在你 prompt 集里被引用的所有 URL 拉出来,按域名归类。会看到三种典型分布:
- 绝大部分来自自有域名 → GEO 靠自有内容。优化路径:你也得做内容矩阵。
- 相当比例来自第三方媒体/平台 → GEO 靠 PR 和外部铺设。优化路径:怎么进这些第三方。
- 两边都有 → 它两边都做且互相引流。这是最强的对手。
判断对手类型,决定你接下来资源该投哪里——写自己的内容,还是去外部铺。
这一层用 Profound、AthenaHQ、OtterlyAI 这类工具能直接出。但第一次建议手算一遍,亲手数过 SoV 才会理解这数字背后的意思。
第二层:内容拆解(对手的内容是怎么赢的)
拆解对手的”招式”。招式可学——拆完之后能直接动手补。
1. 内容矩阵覆盖度。
别只看一个页面。打开对手网站看它有哪几类页面:
- 产品 / 服务页
- 选择指南页(”How to choose X””X buyer’s guide”)
- 成本说明页(”X cost””X pricing”)
- 对比页(”X vs Y”)
- 案例 / 客户故事页
- FAQ 页
- About 页 + 团队页
AI 在不同 prompt 下会引用同一网站的不同页面:成本类 prompt 引成本页,选择类 prompt 引指南页,对比类 prompt 引对比页。矩阵不全等于火力分散——很多决策类 prompt 你根本没参赛资格。
很多 B2B 公司官网只有产品页和案例页,缺选择指南、成本页、对比页。这是最常见的 GEO 内容缺口,也是最容易补的。
2. 单页面结构。
找出被引用最多的那个页面打开看:
- 首段有没有”一句话答案”。 AI 极爱抠首段。50 字以内的直接结论 + 下面展开论证,被抠的概率比”先讲背景再讲答案”高得多。
- H2 是不是疑问句形式。 一个反直觉但合理的观察:被高频引用的页面,H2 经常是直接的疑问句(”How much does X cost?”),不是名词短语(”X 成本分析”)。原因是 AI 在做检索增强生成(RAG)时,倾向把”问题—答案”结构的内容块当成可直接抠取的最小单元——疑问句 H2 + 紧跟答案,正好是 AI 最爱的结构。
- 有没有列表、对比表、FAQ。 AI 抠表格和列表比抠段落容易得多。一篇有 3 个表格的页面,被引用频率经常显著高于同主题的纯文字长文。
- 段落短不短。 80 字以内的短段落更易被 AI 整段引用。500 字大段长文,AI 通常只引第一句。
这一层 Profound 的内容分析模块、AthenaHQ 的 Action Center 都能给到具体页面级建议。但第一次手动看几个页面更有感觉,看多了你会培养出对”AI 友好结构”的直觉。
第三层:信任根基(对手为什么 AI 信它)
第三层是找对手的”根基”。根基难复制——不是改两篇文章就能补的,是长期投入的结果。但根基决定了可追距离。
1. E-E-A-T(经验、专业、权威、可信,Google 评估内容质量的核心框架)。
看三点:
- 作者是不是真人、有没有履历。 打开对手指南页看作者署名。有作者头像、LinkedIn 链接、过往文章列表 → 强信号。作者是”Admin”或没署名 → AI 在 E-E-A-T 上扣分。
- 网站本身有没有真实的 About、案例、原始数据。 检查方法:找对手 About 页,看是否说清楚”我们是谁、做了什么、服务过谁、有什么成绩”。空泛的”我们提供优质服务”对 AI 没有信号价值。
- 品牌在外部的称呼和定位是不是一致。 检查方法:在 Google 搜对手品牌名看前 20 条结果——它在媒体、协会、目录、社媒上的称呼是不是同一个?业务定位是不是一致?
最后一点对 B2B 尤其关键。AI 会同时看”网站怎么说自己”和”外面怎么说它”。两边一致 → 实体清晰;两边打架 → AI 通常宁可不引用。
2. 实体对齐(Entity Alignment)。
AI 是不是反复把这个品牌和某个核心关键词绑在一起?这是 GEO 里最技术、最难复制的一环。两个免费检查方法:
- 去 Google 搜对手品牌名,看右侧 Knowledge Panel 出不出来。 出来了说明 Google 已经把它识别为独立实体,AI 调 Knowledge Graph 时能直接找到。这是最强的实体信号。
- 去 ChatGPT 问 “Tell me about [对手品牌名]”。 看 ChatGPT 能不能准确说出它做什么、服务什么客户、有什么核心特点。能说清楚 → 实体对齐到位;说错或胡编 → 实体对齐有缺口。Claude、Perplexity、Gemini 也跑一遍——Gemini 因为深度依赖 Google Knowledge Graph,是验证实体对齐到不到位的最直接信号。
两个检查都通过的对手是真硬骨头——实体对齐是多年积累的结果,短期难以追平,只能靠长期内容铺设、外部提及一致性、Schema 标注、Wikidata 条目等组合手段慢慢补。这块涉及的技术细节单独讲是另一篇。
第三层很少有现成工具能完整覆盖,主要靠人工诊断 + 长期跟踪。Scrunch AI 的 Replacement Analysis 算第三层维度的延伸,能告诉你”是谁在抢你的位置”,但不能直接告诉你”对方实体根基是怎么搭起来的”。
把三层分析变成一张行动表
很多人拆完写一份”竞对分析报告”就完事——报告没用,能驱动动作的表才有用。
每行最好包含这几列:发现 / 对手做法 / 我的差距 / 下一步动作 / 优先级 / 完成周期 / 对应层级。
关于”完成周期”:这里指动作完成时间,不是见效时间。 GEO 的见效周期通常比内容产出周期长得多——选型指南上线后一般 4–8 周才能在 AI 答案里看到引用变化;Schema/Knowledge Graph 这类信任建设动作见效要按季度算。别把 1 周完成的动作误读成”一周后 AI 就引我了”。
发现 | 对手做法 | 我的差距 | 下一步动作 | 优先级 | 完成周期 | 层级 |
“如何选 XX 供应商”被某协会站高频引 | 有结构化选型指南配对比表 | 我没这个主题 | 产出英文选型指南,配对比表 + FAQ | 高 | 1–2 周 | 第二层 |
行业规范文档反复被 AI 引 | 中立权威信源 | 我的内容里没引规范 | 后续内容精准引用核心行业规范 | 中 | 持续 | 第二层 |
内容对手 B 有完整成本页 | 拆解了多个成本影响因素 | 我没有成本页 | 新建出口报价构成页 | 高 | 1 周 | 第二层 |
对手 A 在 Google Knowledge Panel 能搜到 | 长期外部建设 + Schema 标注 | 我的品牌不在 Knowledge Panel | 启动 Wikidata 条目 + Schema 部署 | 中 | 3–6 月 | 第三层 |
最后一列”层级”是关键——第二层的动作(内容补丁)几周内能完成,第三层的动作(信任建设)按月或按季度计。把它们混在一起规划,资源会乱。
GEO 竞争分析最容易踩的三个坑
只用一个 AI 平台测。 不同模型答案差异比想象中大。ChatGPT 不提你不代表 Perplexity 不提,反过来也成立。至少跑三个。
只看出现次数,不看语境。 被吐槽和被表扬频率一样但价值相反。语境列别省。
只看同行,不看非品牌信源。 你的对手名单里如果一个非品牌信源都没有,那不是没有——是漏了。
第一次做 GEO 竞争分析的最小起步方案
不用买工具。10 个 prompt,3 个 AI 平台(ChatGPT + Perplexity + Google AI Overview),用一张表记录,选 Top 3 对手按三层拆,产出一张行动表。两三天能跑完一轮。
跑完一轮才会知道 GEO 竞对分析是什么——不是研究工具,是练出一种”在 AI 里看自己”的眼力。
判断眼力到没到位有个简单标准:不开任何工具的情况下,看到一个 prompt 答案就能立刻判断”这个引用源是真权威还是凑数的”? 能 → 眼力到位 → 上工具效率会跳一档;不能 → 再跑两轮手动再说。
现在就可以做的第一件事:打开一份新表格,写下你最希望客户在 AI 那里问到的 5 个问题。
GEO 竞争分析的真正难点
GEO 竞对分析的难点不在跑 prompt,在两个地方——A 阶段怎么系统化识别真实对手(特别是非品牌信源),B 阶段怎么按”诊断→拆解→根基”三层分清楚再变成内容动作。多数团队跑完一轮就卡在”写了份报告”那一步,没进到行动闭环,结果是分析做了,优化没动。
我们西品东来在GEO优化项目里跑过不少这类分析,沉淀了一套从 prompt 设计、跨层拆解到行动落地的框架。如果你正在搭这套能力,或者想让我们帮你跑一轮基线分析,可以联系我们聊。
不管是刚要开始第一轮,还是已经跑过几轮——你现在能立刻列出几个具体动作吗? 列不出来,说明分析还停在”看到了”而不是”看清了”。